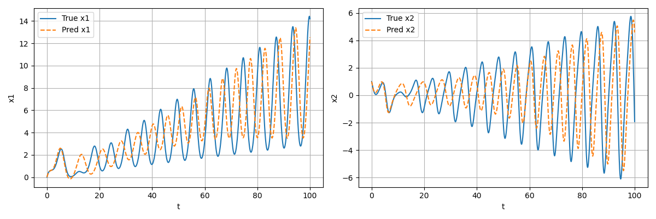
求矩阵特征值与特征向量:乘幂法及其改进算法
研究背景意义
矩阵的特征值计算虽然有比较可靠的理论方法,但是,理论方法只适合于矩阵规模很小或者只是在理论证明中起作用,而实际问题的数据规模都比较大,不太可能采用常规的理论解法。计算机擅长处理大量的数值计算,所以通过适当的数值计算理论,写成程序,让计算机处理,是一种处理大规模矩阵的方法,而且是一种好的方法。乘幂法(又称幂法)是求矩阵按模最大特征值的常用方法,其结构简单、便于使用,在实际工程中应用广泛:
- 在数值分析和优化问题中,乘幂法可通过求解矩阵按模最大特征值来得到其谱半径,从而帮助分析迭代算法的收敛性;
- 在物理学和工程学中,特征值问题常用于分析系统的稳定性、振动频率和模态分析,乘幂法能够有效求解系统的最大特征值,从而帮助理解系统的动态行为;
- 在图像处理中,特征值分解用于图像压缩、特征提取和模式识别,乘幂法可用于求解图像矩阵的最大特征值,从而实现高效的图像处理算法;
- ……
但该方法也存在一定的局限性,其只适用于求矩阵按模最大的特征值,而在实际问题中往往需要求矩阵全部特征值,如在主成分分析中需要求相关矩阵的全部特征值以确定各主成分的贡献率,在求解线性微分方程组中通过求系数矩阵的全部特征值以确定其基础解系;同时该方法在求特定矩阵(如具有一对互为相反数的按模最大特征值的矩阵等)的按模最大特征值时是不收敛的。因此,我们希望以乘幂法基本思想为出发点,在此基础上提出一些改进算法以对其进行泛化,使其能够解决更为广泛且通用的应用场景下的实际问题。
算法基本思想
设n阶矩阵A具有n个线性无关的特征向量
$$
x_1,x_2,…,x_n
$$
相应的特征值
$$
\lambda_1,\lambda_2,…,\lambda_n
$$
满足:
$$
\left|\lambda_1\right|>\left|\lambda_2\right|\geq\left|\lambda_3\right|\geq…\geq\left|\lambda_n\right|
$$
现任取一非零向量u_0,作迭代
$$
u_k=Au_{k-1}, k=0,1,2,…
$$
得到向量序列{u_k}(k=0,1,2,…)。因各特征向量线性无关,故n维向量u_0必可由他们线性表示,即:
$$
u_0=\alpha_{1}x_{1}+\alpha_{n}x_{2}+…+\alpha_{n}x_{n}
$$
显然有:
$$
\begin{aligned}u_{k}&=A^{k}v_{0}=\alpha_{1}A^{k}x_{1}+\alpha_{2}A^{k}x_{2}+\cdots+\alpha_{n}A^{k}x_{n}=\alpha_{1}\lambda_{1}^{k}x_{1}+\alpha_{2}\lambda_{2}^{k}x_{2}+\cdots+\alpha_{n}\lambda_{n}^{k}x_{n}\&=\lambda_{1}^{k}\left[\alpha_{1}x_{1}+\alpha_{2}\left(\frac{\lambda_{2}}{\lambda_{1}}\right)^{k}x_{2}+\cdots+\alpha_{n}\left(\frac{\lambda_{n}}{\lambda_{1}}\right)^{k}x_{n}\right]\end{aligned}
$$
设
$$
\alpha_{1} \neq 0
$$
由
$$
\left|\frac{\lambda_{i}}{\lambda_{1}}\right|<1,i=2,3,\cdots,n
$$
可得:
$$
\operatorname*{lim}{k\to\infty}\frac{u{k}}{\lambda_{1}^{k}}=\operatorname*{lim}{k\to\infty}\frac{\lambda{1}^{k}\left[\alpha_{1}x_{1}+\sum_{i=2}^{n}\alpha_{i}\left(\frac{\lambda_{i}}{\lambda_{1}}\right)^{k}x_{i}\right]}{\lambda_{1}^{k}}=\operatorname*{lim}{k\to\infty}\left[\alpha{1}x_{1}+\sum_{i=2}^{n}\alpha_{i}\left(\frac{\lambda_{i}}{\lambda_{1}}\right)^{k}x_{i}\right]=\alpha_{1}x_{1}
$$
$$
\operatorname*{lim}{k\to\infty}\frac{\left(u{k+1}\right){m}}{\left(u{k}\right){m}}=\operatorname*{lim}{k\to\infty}\frac{\left{\lambda_{1}^{k+1}\left[\alpha_{1}x_{1}+\sum_{i=2}^{n}\alpha_{i}\left(\frac{\lambda_{i}}{\lambda_{1}}\right)^{k+1}x_{i}\right]\right}{m}}{\left{\lambda{1}^{k}\left[\alpha_{1}x_{1}+\sum_{i=2}^{n}\alpha_{i}\left(\frac{\lambda_{i}}{\lambda_{i}}\right)^{k}x_{i}\right]\right}{m}}=\lambda{1}\frac{\left(x_{1}\right){m}}{\left(x{1}\right){m}}=\lambda{1}
$$
这表明向量序列u_k具有收敛性,其收敛速度由比值
$$
\left|\frac{\lambda_{2}}{\lambda_{1}}\right|
$$
确定,该比值越小说明收敛速度越快,比值越接近于1收敛速度就越慢。
同时,该结论表明,当k取得足够大时(在实际应用时往往认为某次迭代前后误差小于设定的误差限即满足该条件),有:
$$
u_{k}≈\lambda_{1}^{k}\alpha_{1}x_{1}, \lambda_{1}≈\frac{\left(u_{k+1}\right)}{\left(u_{k}\right)}
$$
即u_ k可近似看作特征值λ_ 1对应的特征向量(较原特征向量x_ 1而言仅乘上了有限的常数系数,其结果仍为该特征值对应的特征向量),而对应的按模最大特征值λ_ 1的估计值可由前后两次迭代的特征向量u_ k相除得到。
当矩阵的按模最大特征值是重根时,上述结论仍然成立。设λ_ 1为r重根,即:
$$
\lambda_{1}=\lambda_{2}=\cdots=\lambda_{r}
$$
且满足条件
$$
\mid\lambda_{r}\mid>\mid\lambda_{r+1}\mid\geq\cdots\geq\mid\lambda_{n}\mid
$$
则有:
$$
u_{k}=A^{k}u_{0}=\lambda_{1}^{k}\left[\sum_{i=1}^{r}\alpha_{i}x_{i}+\sum_{j=r+1}^{n}\alpha_{j}\left(\frac{\lambda_{j}}{\lambda_{1}}\right)^{k}x_{j}\right]
$$
易推得(式中(u_ k)_ m表示向量u_ k的第m个分量):
$$
\lim_{k\to\infty}\frac{u_{k}}{\lambda_{i}^{k}}=\sum_{i=1}^{^{r}}\alpha_{i}x_{i},\lim_{k\to\infty}\frac{\left(u_{k+1}\right){m}}{\left(u{k}\right){m}}=\lambda{1}
$$
与一般情况略有不同的是,此时
$$
u_{k}≈\lambda_{i}^{k}\sum_{i=1}^{^{r}}\alpha_{i}x_{i}
$$
但事实上我们并没有办法在求解之前事先预知一个矩阵是否具有r重按模最大特征值,因此在实际操作的过程中采用与一般情形相同的处理方式(即认为r=1),所得的向量序列u_k仍然收敛,不影响求解结果。
基于以上的算法原理,可以编写如下MATLAB程序,实现一般情况下矩阵按模最大特征值及其对应特征向量的计算:
1 | function calculatePowerMethod(matrixEdit, iterEdit) |
改进的乘幂法
在实际应用层面,上述的算法逻辑只在一小部分的常规矩阵上对于矩阵的按模最大特征值求解有较好效果。事实上,仅依托以上的代码逻辑进行求解往往会出现以下几大问题:
- 当矩阵A不具有n个线性无关的特征向量时(事先无法判断),乘幂法不适用。
- 当待求取的按模最大特征值abs(λ_ 1)>1时,迭代向量u_ k的各个分量可能会随着abs(λ_ 1)^k变得很大而使计算机“上溢”;而当待求取的按模最大特征值abs(λ_ 1)<1时,迭代向量u_ k的各个分量可能会随着abs(λ_ 1)^k变得很小使u_k成为零向量。
- 矩阵的按模最大特征值是一对相反数。
- 矩阵的按模最大特征值是一对共轭复数。
(上述算法中还给出了α_1≠0的假设,事实上如果不满足这一点也不影响乘幂法的成功使用。因为舍入误差的影响,在迭代某一步会产生u_k在x_1方向上的分量不为零,以后的迭代仍会收敛)
针对问题1,我们暂时无法提出具有针对性的解决方案,但后续的实际测试证明,当迭代次数k足够大时,我们针对问题3所提出的改进方案在该种情况下相比基本算法能够有更好的收敛性(收敛更快);针对问题2,我们可以通过将向量序列u_k进行规范化处理,限制向量的模在特定小范围内,防止计算机运算的上下溢出;针对问题3,我们在原有的乘幂法算法思想的基础上进行了改进,改进后的算法能够有效对原算法无法求解(不收敛)的按模最大特征值互为相反数的矩阵的按模最大特征值进行有效求解;针对问题4,我们目前还没有找到有效的解决方案。
迭代向量的归一化
设迭代向量u为非零向量,将其归一化得到向量
$$
y=\frac{u}{max(u)}
$$
其中max(u)表示向量u的模最大的分量(即向量的无穷范数)。这样的规范化会保证每一次迭代后得到的新的迭代向量的模最大分量均为1,这有效起到了限制迭代向量分量范围的作用,能够很好地解决上述提到的问题2。值得注意的是,对向量规范化的方式并不只有归一化这一种,实际上可以使用任意一种范数对向量进行规范化处理,如2范数等。可以证明,对于基于不同范数的归一化都有相同的向量序列收敛结论,下面以无穷范数为例给出基本的证明。(显然这样的规范化只是在原有的向量基础上除以了某一个常数,这并不会改变向量序列的收敛性)
取初始向量
$$
u_{0}\neq0
$$
规范化得
$$
y_{0}=\frac{u_{0}}{\max(u_{0})}
$$
构造向量序列:
$$
\begin{aligned}
&u_{1}=Ay_{0}=\frac{Au_{0}}{\max(u_{0})},
&y_{1}=\frac{u_{1}}{\max(u_{1})}=\frac{Au_{0}}{\max(Au_{0})}\
&u_{2}=Ay_{1}=\frac{A^{2}u_{0}}{\max(Au_{0})},
&y_{2}=\frac{u_{2}}{\max(u_{2})}=\frac{A^{2}u_{0}}{\max(A^{2}u_{0})}\
&……\
&u_{k}=Ay{{k-1}}=\frac{A^{k}u{0}}{\max(A^{k-1}u_{0})},
&\quad y_{k}=\frac{u_{k}}{\max(u_{k})}=\frac{A^{k}u_{0}}{\max(A^{k}u_{0})}
\end{aligned}
$$
结合乘幂法基本算法中已经证明的结论
$$
A^{k}u_{0}=u_{k}≈\lambda_{1}^{k}\alpha_{1}x_{1}
$$
则有:
$$
\lim_{k\to\infty}y_{k}=\frac{x_{1}}{\max(x_{1})},
\lim_{k\to\infty}\max(u_{k})=\lambda_{1}
$$
这表明此时y_ k可近似看作特征值λ_ 1对应的特征向量(较原特征向量x_ 1而言仅进行了归一化处理,其结果仍为该特征值对应的特征向量),而对应的按模最大特征值λ_ 1的估计值可近似看作未归一化前的迭代向量最大分量值max(u_k)。
基于以上的算法原理,可以编写如下MATLAB程序,实现归一化处理下矩阵按模最大特征值及其对应特征向量的计算:
1 | function calculatePowerMethod(matrixEdit, iterEdit) |
归一化乘幂法的进一步改进
针对问题3,从其基本情形出发(其他条件与先前保持一致),即有:
$$
\mid\lambda_1\mid=\mid\lambda_2\mid>\mid\lambda_3\mid\geqslant\cdotp\cdotp\cdotp\geqslant\mid\lambda_n\mid,\lambda_1=-\lambda_2
$$
在矩阵按模最大特征值为一对相反数的情况下,原迭代向量序列中各相邻向量的比值极限发散:
$$
\lim_{k\to\infty}\frac{\boldsymbol{u}_{k+1}}{\boldsymbol{u}k}=\lambda_1\lim{k\to\infty}\frac{a_1\boldsymbol{x}_1+(-1)^{k+1}a_2\boldsymbol{x}2+\boldsymbol{\varepsilon}{k+2}}{a_1\boldsymbol{x}_1+(-1)^ka_2\boldsymbol{x}_2+\boldsymbol{\varepsilon}_k}
$$
说明在该种情况下,采用原有的乘幂法基本算法,得到的迭代向量序列并不收敛,无法得到稳定的矩阵按模最大特征值数值求解结果。
我们在原有算法的基础上进行了一定的改进,构造了新的迭代向量序列,使其对于矩阵按模最大特征值为一对相反数的情况也能保证收敛,从而可以对该情况下的矩阵按模最大特征值进行有效求解。
先从较为简单的非归一化迭代入手,同样取迭代向量序列u_k,其初始非零向量u_0满足:
$$
u_0=\alpha_{1}x_{1}+\alpha_{n}x_{2}+…+\alpha_{n}x_{n}(\alpha_{1}\neq0)
$$
则有:
$$
\boldsymbol{u}{k}=\boldsymbol{A}^{k}\left(\sum{i=1}^{n}a_{i}\boldsymbol{x}{i}\right)=\lambda{1}^{k}\left(a_{1}\boldsymbol{x}{1}+(-1)^{k}a{2}\boldsymbol{x}{2}+\sum{i=3}^{n}\left(\frac{\lambda_{i}}{\lambda_{1}}\right)^{k}a_{i}\boldsymbol{x}{i}\right)=\lambda{1}^{k}(a_{1}\boldsymbol{x}{1}+(-1)^{k}a{2}\boldsymbol{x}{2}+\boldsymbol{\varepsilon}{k}),\lim_{k\to\infty}\varepsilon_{k}=0
$$
于是可得到:
$$
\lim_{k\to\infty}\frac{u_{k+2}}{u_{k}}=\lambda_{1}^{2}\lim_{k\to\infty}\frac{\alpha_{1}x_{1}+(-1)^{k+2}\alpha_{2}x_{2}+\varepsilon_{k+2}}{\alpha_{1}x_{1}+(-1)^{k}\alpha_{2}x_{2}+\varepsilon_{k}}=\lambda_{1}^{2}
$$
且有:
$$
\lim_{k\to\infty}\frac{u_{k+1}+\lambda_1u_k}{\lambda_1^{k+1}}=2\alpha_1x_1
$$
以上结果说明,在矩阵按模最大特征值为一对相反数(正值λ_ 1,负值λ_ 2)的情形下,若采用原有的迭代向量序列,对序列中的向量一隔一取出,构成的新序列是收敛的,且新序列中的相邻两项向量的比值极限为矩阵按模最大特征值的平方;同时,u_ {k+1}+λ_ {1}u_ {k}可近似看作λ_ {1}的特征向量,同理u_ {k+1}+λ_ {2}u_ {k}也可近似看作λ_ {2}的特征向量。
易证该方法对于规范化后的向量序列也具有相同的收敛性,在此不额外给出证明。
在实际编程实现算法时,为尽可能地节省算力与内存并提高计算效率,我们不会预先求取最大迭代次数内每一次迭代的结果再将其分为两个向量序列判断其是否收敛(相邻向量插值小于设定误差限),而是需要结合上述改进算法与逐步迭代过程,对于每一次迭代的求解过程进行逻辑优化,优化后的逻辑如下所示(u_k代表规范化后的迭代向量序列,采用2范数方式进行规范化,k=1,2,…):
若
$$
\left|\frac{\left(\boldsymbol{u}_{k+2}^{(1)}\right)_i}{\left(\boldsymbol{u}_k^{(1)}\right)i}-\frac{\left(\boldsymbol{u}{k+1}^{(1)}\right)i}{\left(\boldsymbol{u}{k-1}^{(1)}\right)_i}\right|<\varepsilon:,\left|\frac{\left(\boldsymbol{u}_{k+2}^{(1)}\right)i}{\left(\boldsymbol{u}{k+1}^{(1)}\right)i}-\frac{\left(\boldsymbol{u}{k+1}^{(1)}\right)_i}{\left(\boldsymbol{u}_k^{(1)}\right)i}\right|<\varepsilon:
$$
则取矩阵按模最大特征值
$$
\lambda_1=\frac{(\boldsymbol{u}{k+2}^{(1)})i}{(\boldsymbol{u}{k+1}^{(1)})i}
$$
对应的特征向量
$$
x_1=u{k+2}^{(1)}
$$若
$$
\left|\frac{\left(\boldsymbol{u}_{k+2}^{(1)}\right)_i}{\left(\boldsymbol{u}_k^{(1)}\right)i}-\frac{\left(\boldsymbol{u}{k+1}^{(1)}\right)i}{\left(\boldsymbol{u}{k-1}^{(1)}\right)_i}\right|<\varepsilon:,\left|\frac{(\boldsymbol{u}{k+2}^{(1)})i}{(\boldsymbol{u}{k+1}^{(1)})i}-\frac{(\boldsymbol{u}{k+1}^{(1)})i}{(\boldsymbol{u}k^{(1)})i}\right|>\varepsilon:
$$
则取矩阵按模最大特征值
$$
\lambda_1=\pm\sqrt{\frac{(\boldsymbol{u}{k+2}^{(1)})i}{(\boldsymbol{u}{k}^{(1)})i}}
$$
对应的特征向量
$$
x_1=\frac{u{k+2}^{(1)}+\lambda_1u{k+1}^{(1)}}{\parallel u{k+2}^{(1)}+\lambda_1u{k+1}^{(1)}\parallel_2}
$$
基于以上的算法原理,可以编写如下MATLAB程序,实现矩阵按模最大特征值及其对应特征向量求解的改进算法,以解决矩阵按模最大特征值可能为一对相反数的特殊情况:
1 | function calculatePowerMethod1(matrixEdit, iterEdit, fig) |
求实对称矩阵的全部特征值
我们知道,实对称矩阵的不同特征值对应的特征向量一定是正交的,因此,可以通过幂法迭代得到矩阵的主特征值λ_ 1和主特征向量x_ 1 ,再重新给出一个新的与v_ 0线性无关的初始迭代向量v_ 1,使v_ 1和x_ 1正交化, 则可以由幂法迭代出矩阵的特征值λ_ 2和特征向量x_ 2。同样使新给出的初始迭代向量v_ 3和x_ 1、x_ 2正交 化,则可以由幂法得到λ_ 3和x_ 3。以此类推,可以计算出矩阵的全部特征值和特征向量。具体证明过程详见参考文献[3],这里仅给出基于上述改进算法的完整算法逻辑:
令
$$
A_j=\mathbf{A}{j-1}-\lambda{j-1}\boldsymbol{x}{j-1}\boldsymbol{x}{j-1}^{\mathrm{T}}(j=2,3,\cdots n)
$$
采取与先前完全相同的迭代向量序列构造方式,有如下判断逻辑(u_k代表规范化后的迭代向量序列,采用2范数方式进行规范化,k=1,2,…):
若
$$
\left|\frac{(u_{k+2}^{(j)})i}{(u_k^{(j)})i}-\frac{(u{k+1}^{(j)})i}{(u{k-1}^{(j)})i}\right|<\varepsilon:,\quad\left|\frac{(u{k+2}^{(j)})i}{(u{k+1}^{(j)})i}-\frac{(u{k+1}^{(j)})i}{(u_k^{(j)})i}\right|<\varepsilon:,
$$
且满足
$$
{|x{m}^{\mathrm{T}}v{k+2}^{(j)}|<\varepsilon}\left(m=1,2,\cdots,j-1\right)
$$
则取矩阵按模最大特征值
$$
{\lambda{j}}=\frac{\left(\boldsymbol{u}{k+2}^{(j)}\right){i}}{\left(\boldsymbol{u}{k+1}^{(j)}\right){i}}
$$
对应的特征向量
$$
x_{j}=\boldsymbol{u}_{k+2}^{(j)}
$$若
$$
\left|\frac{(u_{k+2}^{(j)})i}{(u_k^{(j)})i}-\frac{(u{k+1}^{(j)})i}{(u{k-1}^{(j)})i}\right|<\varepsilon:,\quad\left|\frac{(u_{k+2}^{(j)})_i}{(u_{k+1}^{(j)})_i}-\frac{(u_{k+1}^{(j)})_i}{(u_k^{(j)})_i}\right|>\varepsilon:,
$$
且满足
$$
\left|\boldsymbol{x}{m}^{\mathrm{T}}\frac{\boldsymbol{u}{k+2}^{(j)}+\lambda_{j}\boldsymbol{u}{k+1}^{(j)}}{\parallel\boldsymbol{u}{k+2}^{(j)}+\lambda_{j}\boldsymbol{u}{k+1}^{(j)}\parallel{2}}\right|<\varepsilon\quad(m=1,2,\cdots,j-1)
$$
则取矩阵按模最大特征值
$$
\lambda_{j}=\pm\sqrt{\frac{(\boldsymbol{u}{k+2}^{(j)}){i}}{(\boldsymbol{u}{k}^{(j)}){i}}}
$$
对应的特征向量
$$
\quad x_{j}=\frac{\boldsymbol{u}{k+2}^{(j)}+\lambda{j}\boldsymbol{u}{k+1}^{(j)}}{\parallel\boldsymbol{u}{k+2}^{(j)}+\lambda_{j}\boldsymbol{u}{k+1}^{(j)}\parallel{2}}
$$
基于以上的算法原理,可以编写如下MATLAB程序,实现矩阵按模最大特征值及其对应特征向量求解的改进算法,并对于实对称矩阵的全部特征值进行依次求解(每次运行该函数进行一个特征值的求解,代码中省去了存储用于求解下一个特征值的矩阵作为全局变量的部分):
1 | function calculatePowerMethod2(iterEdit, fig) |
数据测试实验
针对以上提到的乘幂法及其改进算法,将其MATLAB求解代码整合进GUI中,并对求解过程中矩阵按模最大特征值随迭代次数增加的收敛情况进行可视化,基本界面如下:
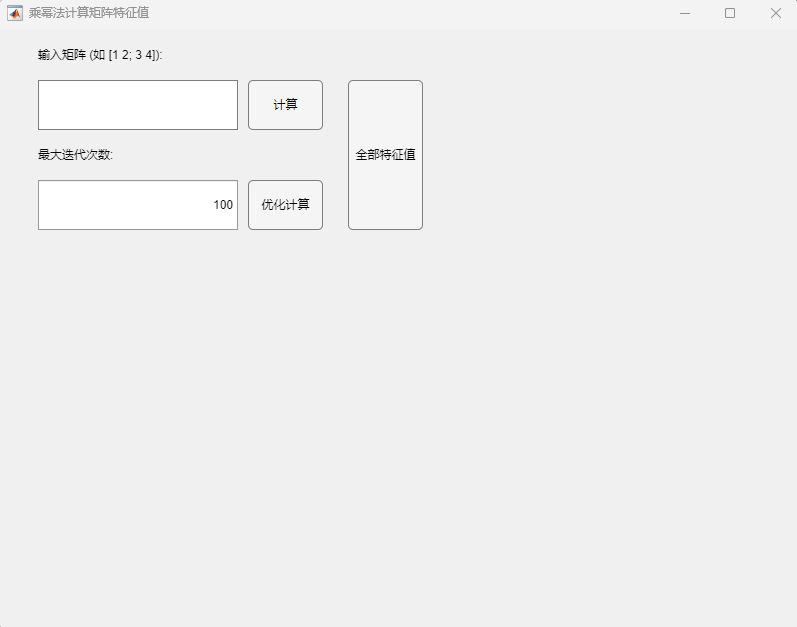
乘幂法基础算法
将待求解的矩阵按照格式要求输入框体内,并指定最大迭代次数(默认为100次),按下“计算”控件可以利用基础的乘幂法(归一化版本)对矩阵按模最大特征值及其对应特征向量进行求解,同时会调用MATLAB中自带的矩阵特征值求解函数eig()对求解结果进行验证。
例:矩阵(特征值为-1、3、5)
$$
A=\begin{pmatrix}1&-1&2\-2&0&5\6&-3&6\end{pmatrix}
$$
程序求解与可视化结果:
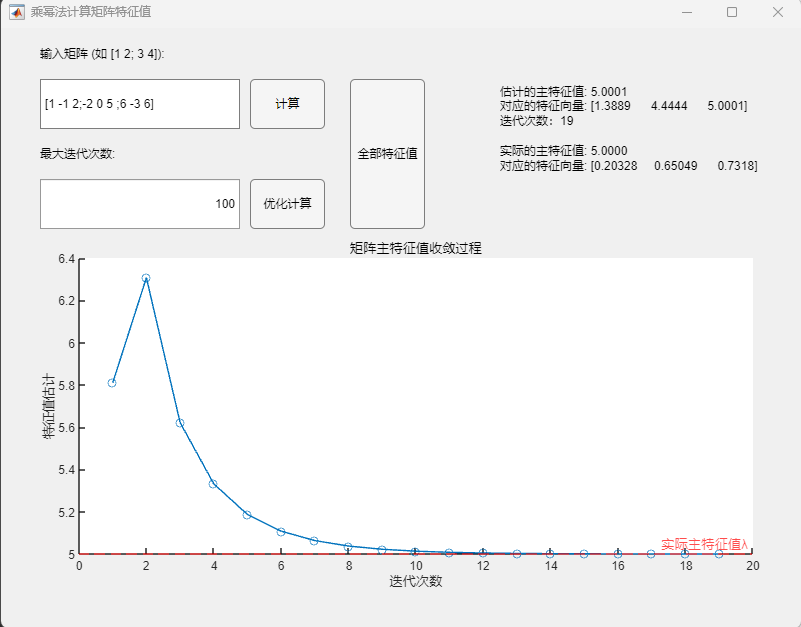
可以发现,估计的主特征值与实际的主特征值在限定的精度内基本一致,对应的特征向量相差了相同的倍数,也可视为正确求解。
乘幂法改进算法
将待求解的矩阵按照格式要求输入框体内,并指定最大迭代次数(默认为100次),按下“优化计算”控件可以利用改进的乘幂法(归一化版本)对矩阵按模最大特征值及其对应特征向量进行求解,同时会调用MATLAB中自带的矩阵特征值求解函数eig()对求解结果进行验证。
例1:矩阵(特征值为-1、3、5)
$$
A=\begin{pmatrix}1&-1&2\-2&0&5\6&-3&6\end{pmatrix}
$$
程序求解与可视化结果:
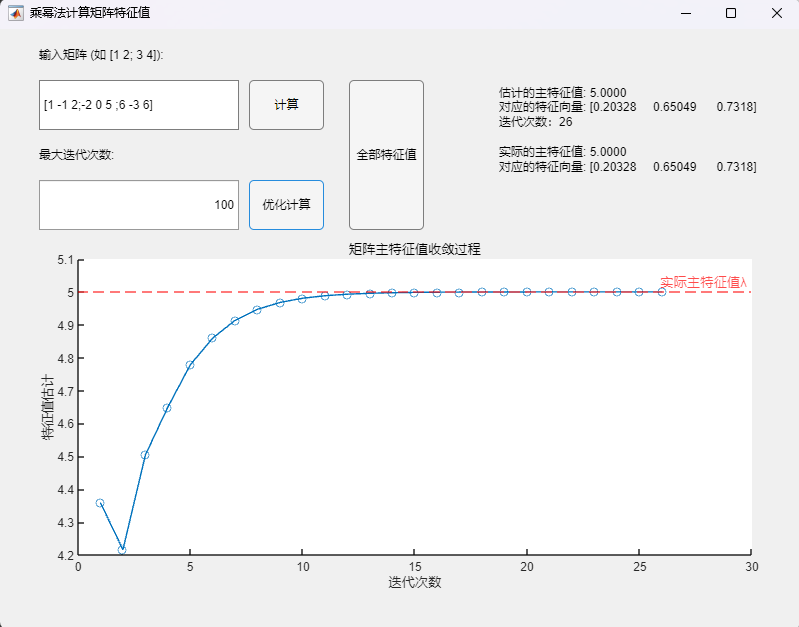
可以发现,估计的主特征值与实际的主特征值在限定的精度内保持一致,通过该算法计算得到的对应特征向量也与MATLAB自带函数(基于 Cholesky 分解/QR分解方法的特征值求解)的求解结果在限定精度内完全一致,但计算需要的迭代次数较基础算法而言有明显增加。
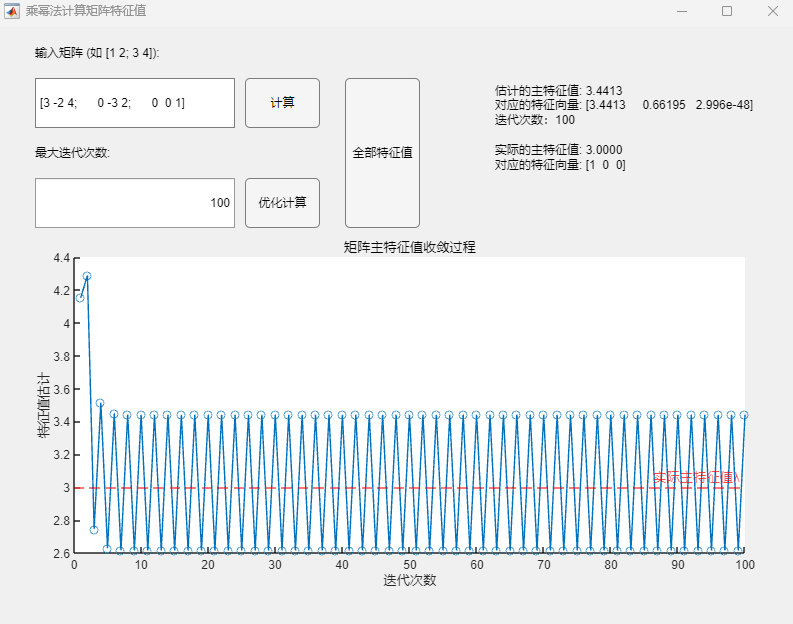
例2:矩阵(特征值为3、-3、1,按模最大特征值为一对相反数)
$$
A=\begin{pmatrix}3&-2&4\0&-3&2\0&0&1\end{pmatrix}
$$
程序求解与可视化结果:
调用乘幂法基本算法:
调用乘幂法改进算法:
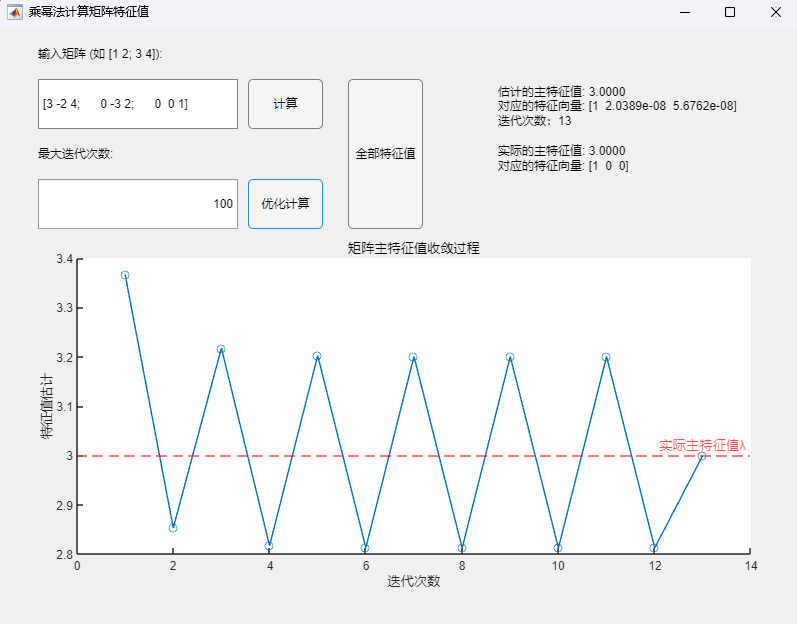
可以发现:
- 调用基础算法时,迭代向量序列在设定的最大迭代次数内并不收敛,最终的求解结果也与实际按模最大特征值有较大误差;
- 而调用改进算法时,尽管从主特征值收敛过程的可视化结果中无法确定向量序列的收敛性(实际上原序列仍发散),但序列中的向量一隔一选取构成的新序列(图像中对应迭代次数全为奇数/偶数的震荡单边)已由程序判断收敛,且估计的主特征值与实际的主特征值在限定的精度内保持一致,通过该算法计算得到的对应特征向量也与MATLAB自带函数(基于 Cholesky 分解/QR分解方法的特征值求解)的求解结果在限定精度内完全一致。
例3:3阶矩阵(特征值为3(重根),但不具有3个线性无关的特征向量)
$$
A=\begin{pmatrix}3&1&0\0&3&1\0&0&3\end{pmatrix}
$$
程序求解与可视化结果:
调用乘幂法基本算法(最大迭代次数100):
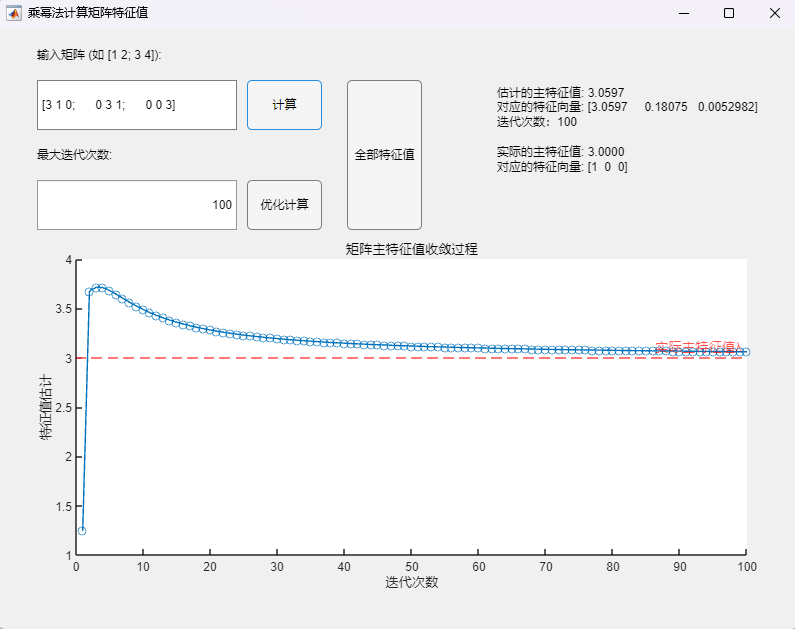
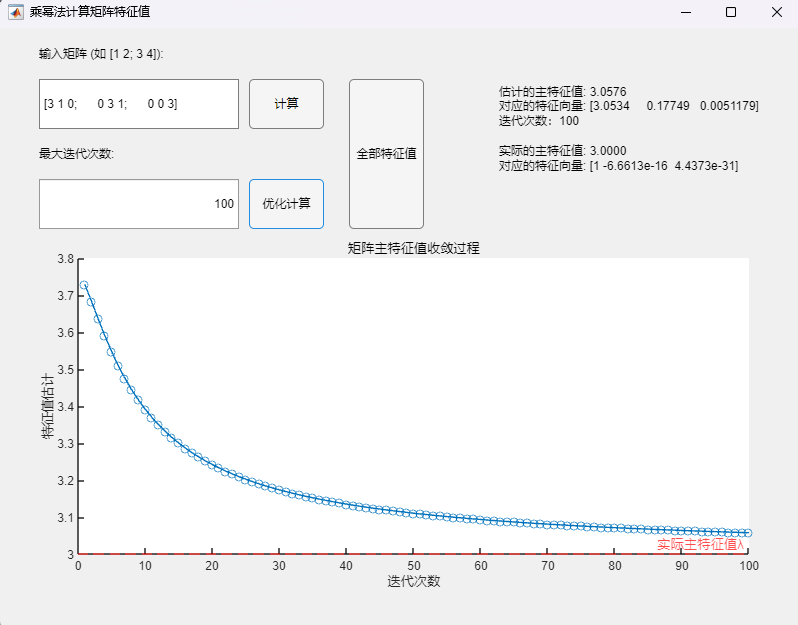
调用乘幂法改进算法(最大迭代次数100):
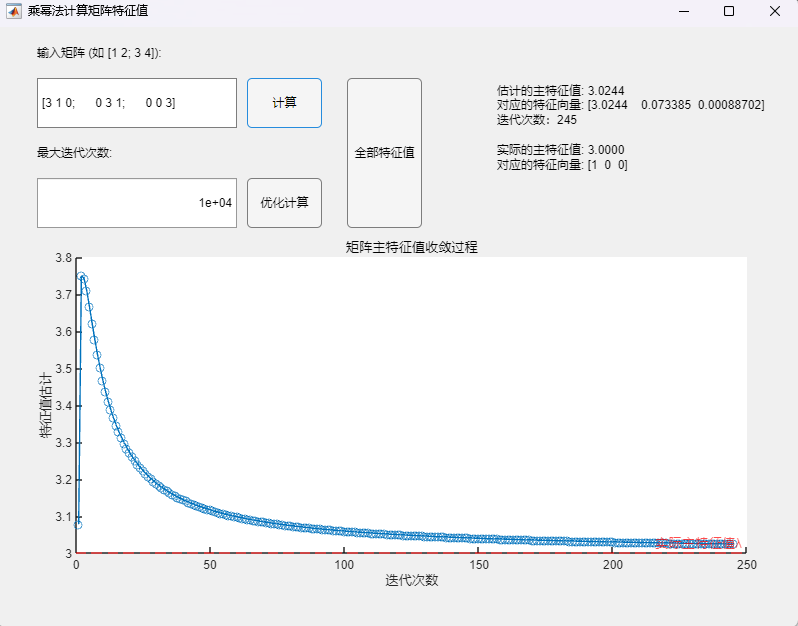
调用乘幂法基本算法(最大迭代次数10000):
调用乘幂法改进算法(最大迭代次数10000):
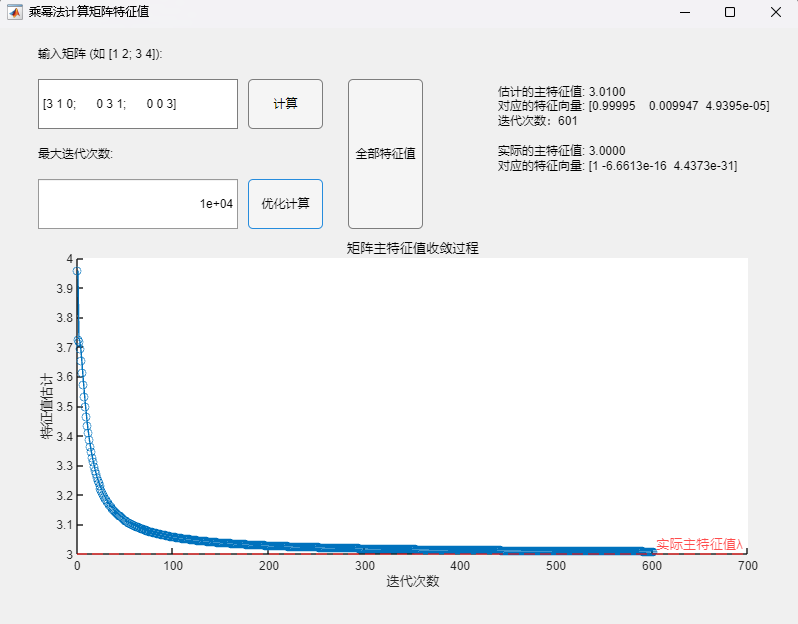
可以发现,当矩阵不具有n个线性无关的特征向量时,乘幂法从理论上讲不再适用(不满足假设条件),但实际测试可以发现:
- 当最大迭代次数设置较小(100)时,两种方法均未呈现数值上的收敛(两次迭代间误差不超过设定误差限10^(-4)),所求得的主特征值与对应特征向量与真实值之间均有明显误差;
- 当最大迭代次数设置足够大(10000)时,两种方法在迭代次数达到10^2数量级时实现了数值上的收敛(两次迭代间误差不超过设定误差限10^(-4)),但在停止迭代后,通过乘幂法基础算法求得的主特征值与对应特征向量与真实值之间仍有明显误差,而通过改进算法求得的主特征值与对应特征向量与真实值已经基本接近,但改进算法所需要的迭代次数也明显更多。
但总的来说,从理论角度出发,在这种情况下乘幂法已不再适用,本例的情况仅为收敛较慢,此时改进算法相较于基础算法有更好的精度;但也会有不收敛的情况,此时两种方法均会有比较大的误差,而这是无法事先判断的,因此在使用乘幂法时还是尽量避免该种情况,或者说在优化算法仍然无法快速收敛的情况下需要注意到矩阵不具有n个线性无关的特征向量的特殊情况,此时应选取其他合适的特征值求解算法。
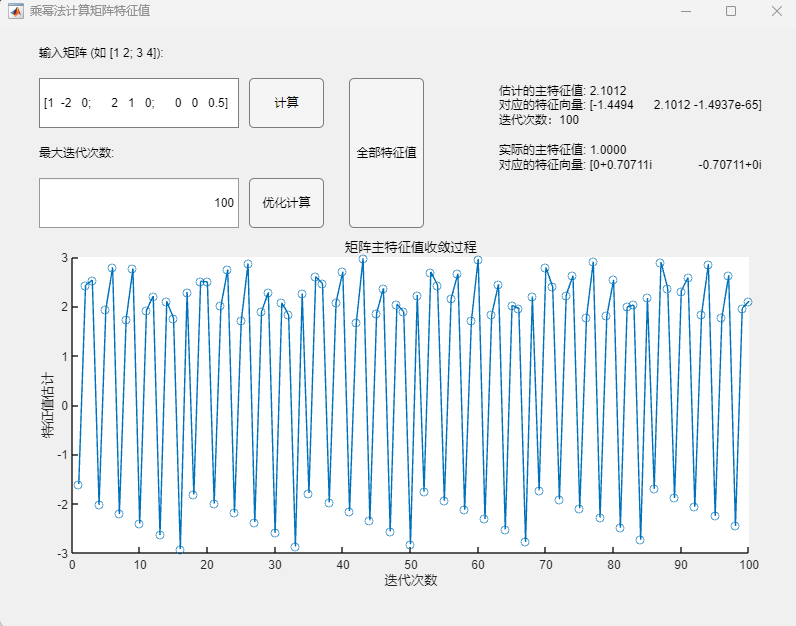
例4:矩阵(特征值为1+2i、1-2i、0.5,按模最大特征值为一对共轭复数)
$$
A=\begin{pmatrix}1&-2&0\2&1&0\0&0&0.5\end{pmatrix}
$$
程序求解与可视化结果:
调用乘幂法基本算法:
调用乘幂法改进算法:
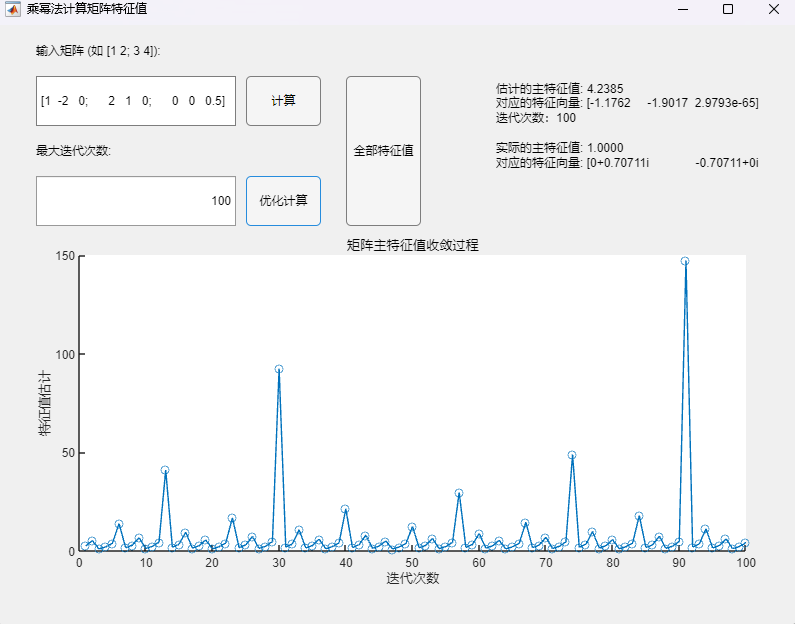
此情况下两种乘幂法均呈现了极大的不稳定性,无法正确求解。
求实对称矩阵的全部特征值
例1:矩阵(特征值为-1、3、5)
$$
A=\begin{pmatrix}1&-1&2\-2&0&5\6&-3&6\end{pmatrix}
$$
程序求解与可视化结果:
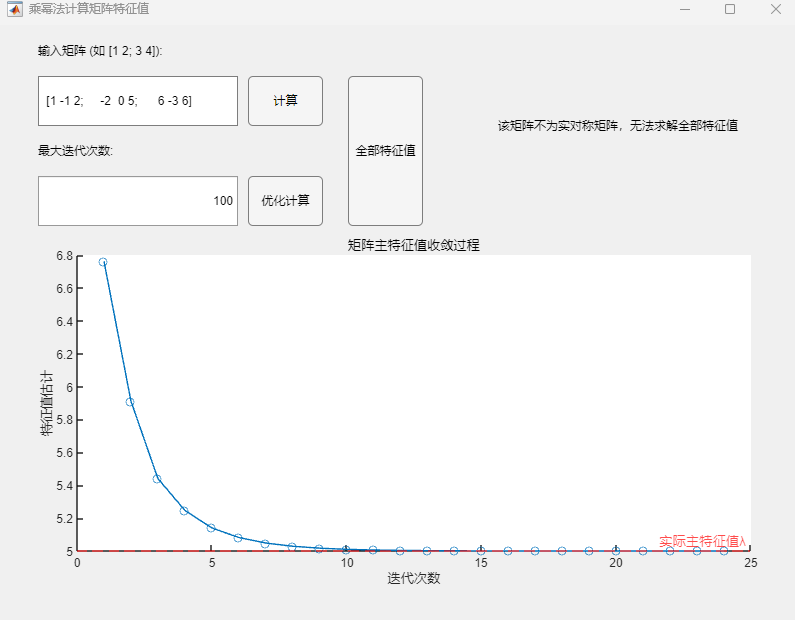
该矩阵不为对称矩阵,无法通过上述算法实现全部特征值的求解,为排错示例。
例2:对称矩阵(特征值为1、2、4)
$$
A=\begin{pmatrix}3&1&1\1&2&0\1&0&2\end{pmatrix}
$$
程序求解与可视化结果:
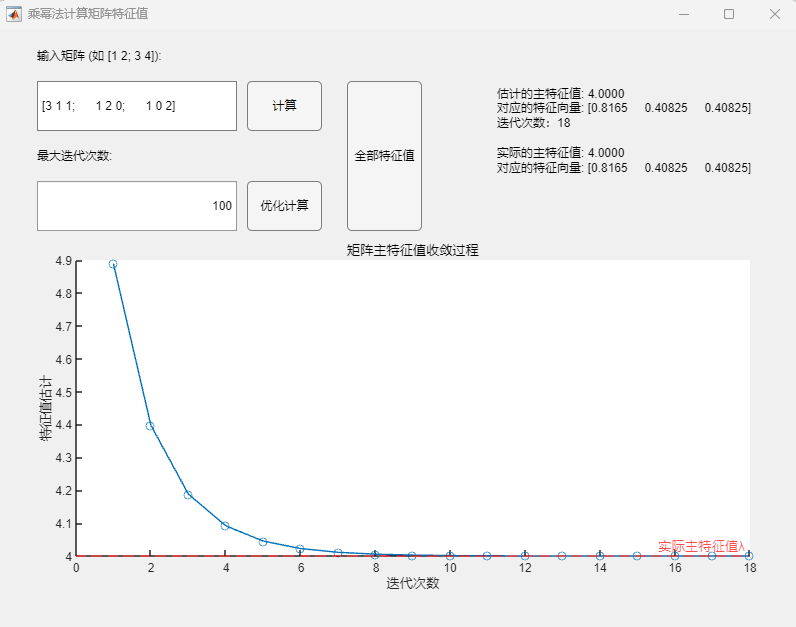
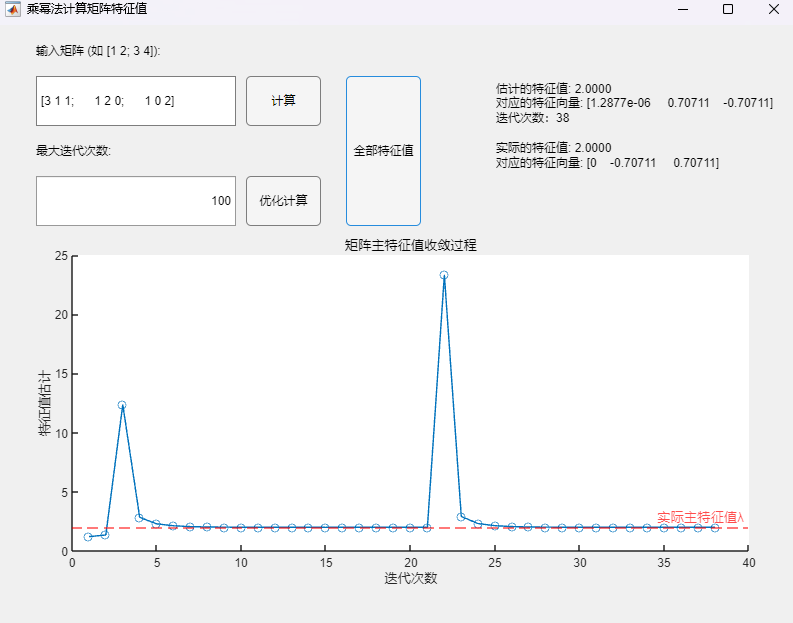
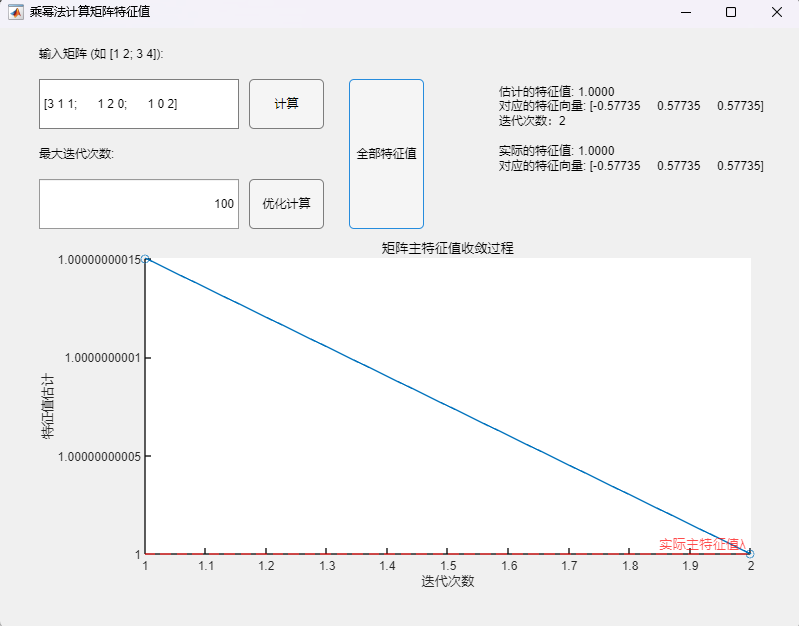
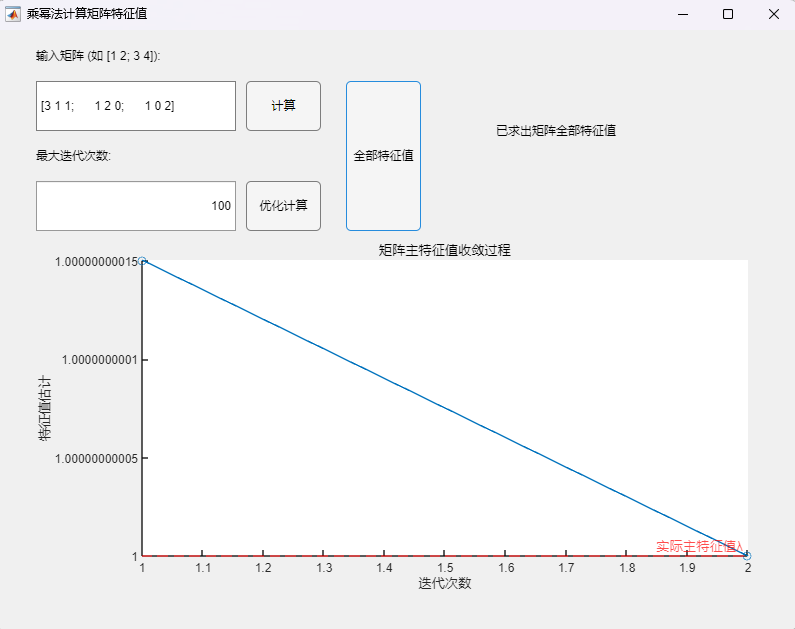
可以看到,该算法可以用于正确求取实对称矩阵的所有特征值及其相应的特征向量,求解结果与MATLAB自带函数(基于 Cholesky 分解/QR分解方法的特征值求解)的求解结果在限定精度内完全一致。
例3:对称矩阵(特征值为2、1、-1)
$$
A=\begin{pmatrix}1&1&0\1&0&1\0&1&1\end{pmatrix}
$$
程序求解与可视化结果:
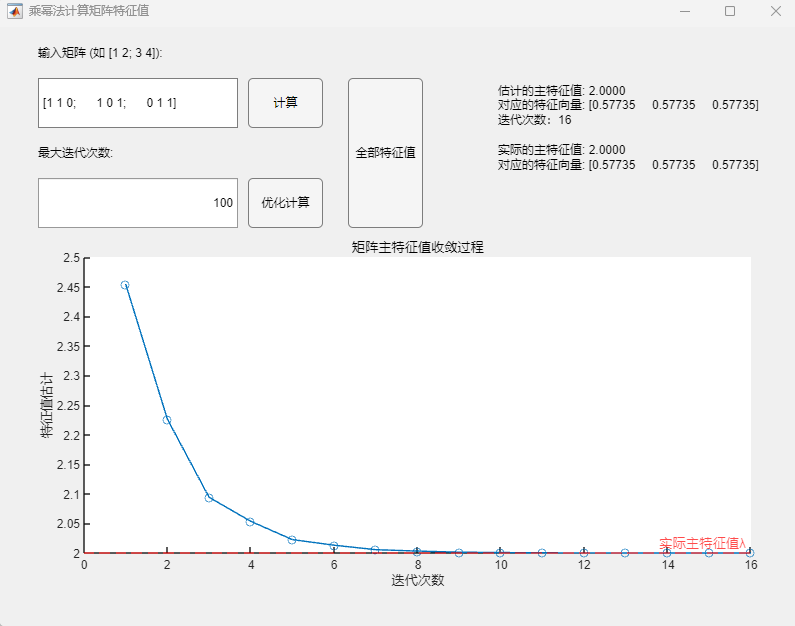
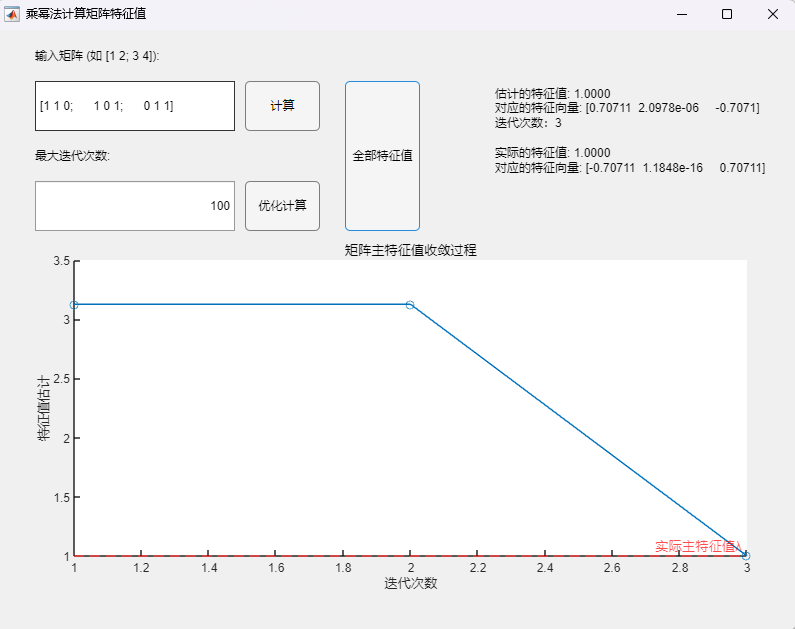
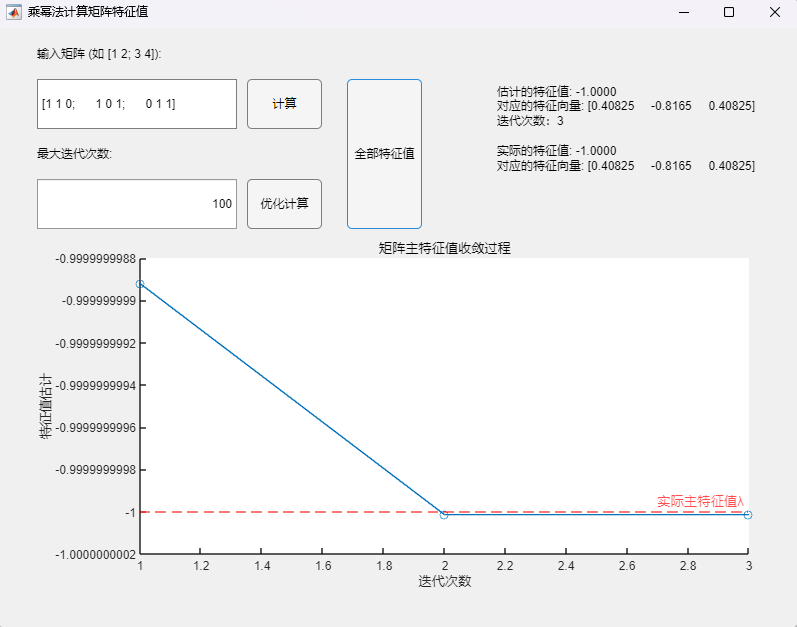
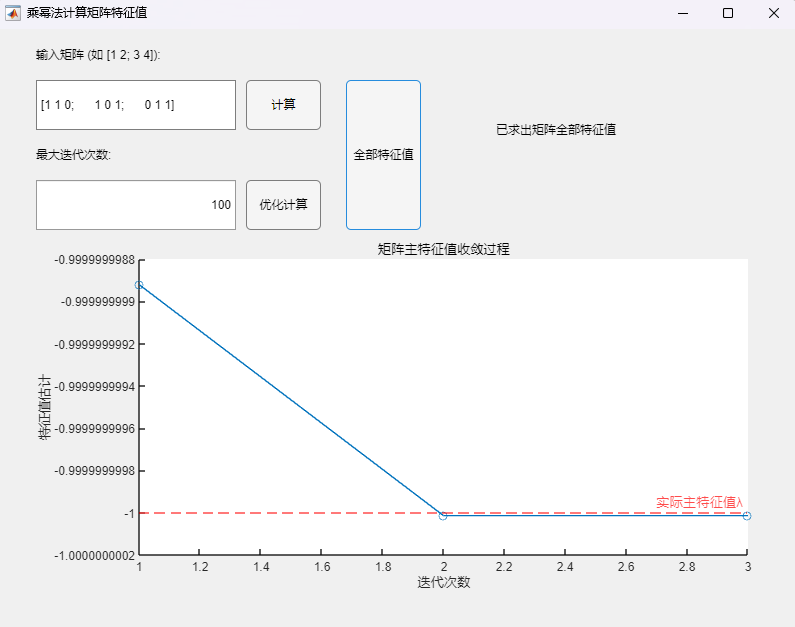
可以看到,即使在矩阵的次主特征值为一对相反数的情况下,该算法也可以用于正确求取实对称矩阵的所有特征值及其相应的特征向量,求解结果与MATLAB自带函数(基于 Cholesky 分解/QR分解方法的特征值求解)的求解结果在限定精度内完全一致。
参考文献
[1] 王开荣,杨大地编著.应用数值分析[M].高等教育出版社,2010.
[2] 曹连英,曲智林,杨瑞智.基于幂法的求实对称矩阵特征值的注记[J].大学数学,2024,40(04):67-72.
[3] 曾莉,肖明.计算实对称矩阵特征值特征向量的幂法[J].南昌大学学报(理科版),2016,40(04):399-402.
[4] 张青,苟国楷,吕崇德.乘幂法的改进算法[J].应用数学与计算数学学报,1997,(01):51-55.
[5] 马志勇,方珑.矩阵特征值求解及其在图像压缩中的应用[J].上海第二工业大学学报,2012,29(04):315-318.
求矩阵特征值与特征向量:乘幂法及其改进算法