PaLM-E:An Embodied Multimodal Language Model
Date:2023-3-6
论文主页:https://palm-e.github.io/
论文链接:PaLM-E: An Embodied Multimodal Language Model
模型架构实现:kyegomez/PALM-E: Implementation of “PaLM-E: An Embodied Multimodal Language Model”
提出大型具身多模态模型PaLM-E(-562B),直接将现实世界的连续传感器模态(视觉【图像】+连续状态估计)融入语言模型(文本输入),从而建立词语与感知之间的联系。在预训练的大型语言模型基础上,端到端地训练【图像+连续状态+文本】的混合编码语句,用于机器人操作顺序规划(推理)、视觉问答(VQA)、图像/视频场景描述等具身任务,将视觉-语言领域的知识迁移到具身推理中。
该模型可基于多种观察模态,在多种具身设备上处理各种具身推理任务,并且具有良好的正向迁移性能【模型受益于跨互联网规模的语言、视觉和视觉-语言领域的多样化联合训练】。在机器人任务上训练后的模型还具有很好的视觉-语言通用性,在OK-VQA数据集上达到了SOTA,并且在参数规模增加时保留了通用的语言能力。
images/palm-e/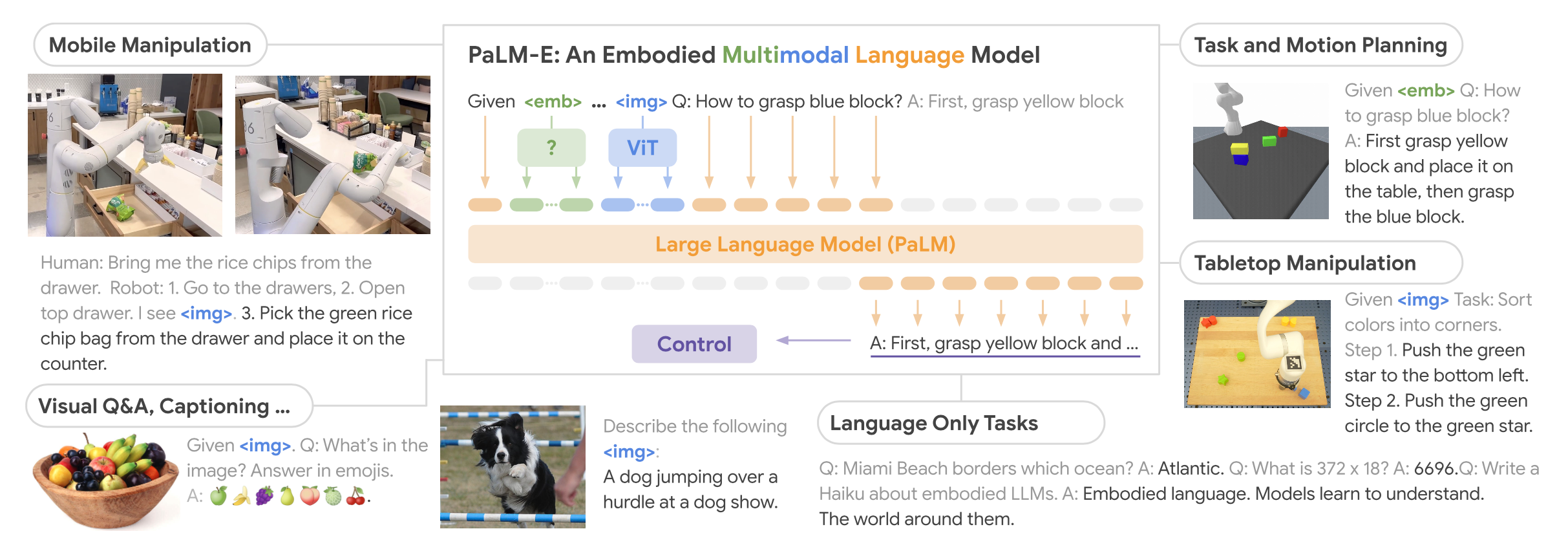
连续状态:来自于机器人的各种传感器的观测结果
VQA【visual-question-answering】:一种基本的多模态任务,结合视觉信息回答问题(V-Q为输入,A为输出)
OK-VQA:基于外部知识的VQA数据集,在COCO数据集上改进补充而来

Background
- 尽管LLM具有强大的推理能力,在海量文本数据上训练的LLM其生成结果可能会与真实物理世界产生关联,但针对更广泛的现实世界问题(CV/Robotics, etc.),在实际应用落地时,显然更重要的是将LLM生成的表示结果和现实世界的视觉和物理传感器模态连接起来。
- 先前的工作在决策时简单地将LLM的输出与学习到的机器人执行策略和可供函数连接起来,但受限于LLM本身仅提供文本输入,这在许多场景几何配置重要的任务中是不够的。
- 当前最先进的视觉-语言模型在典型的视觉-语言任务(如VQA)上训练后,无法直接解决机器人推理任务。
可供函数(affordance function):描述事物提供的行为可能
Model
Multi-model sentences——不同模态的对齐
显然要将高维的感知数据降到和文本相同的维度直接嵌入会造成较大程度的失真,因此所谓的对齐是将文本Token和连续感知状态都映射到同一个嵌入空间χ中,对于不同的数据需要采用不同的映射方法。
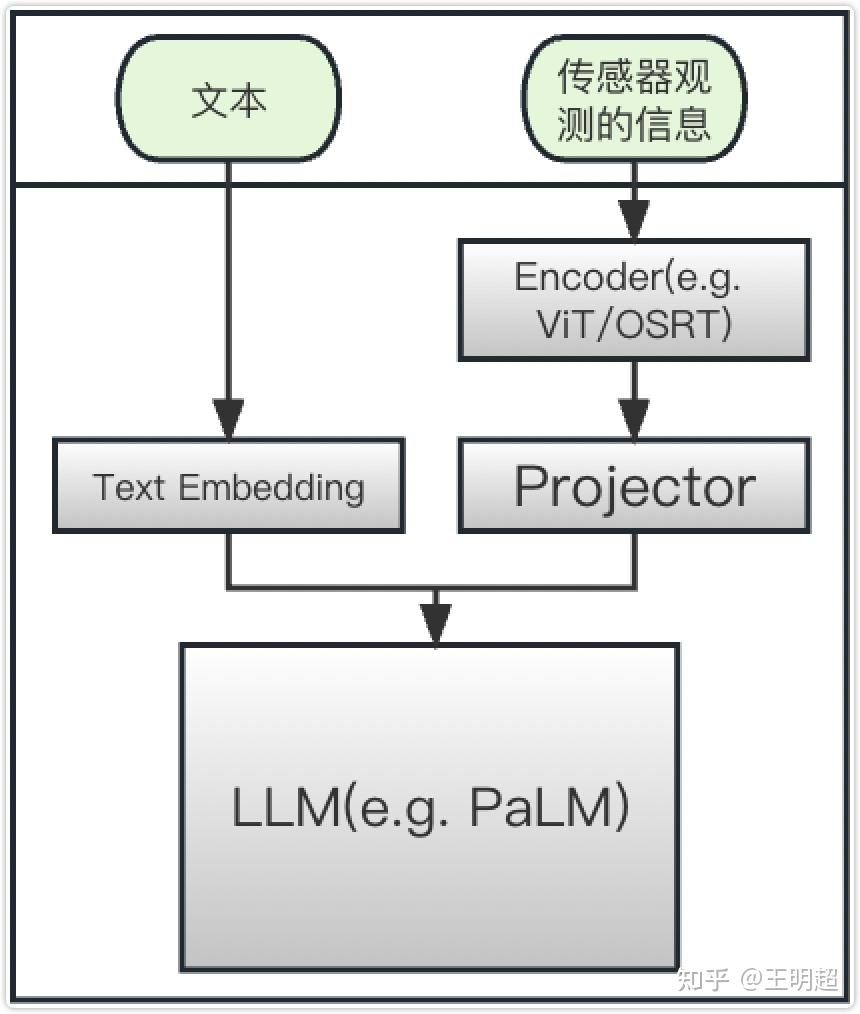
Token embedding space——将文本映射至嵌入空间
对于单个文本token ω而言,需要通过映射γ将其映射到嵌入空间χ中的k维向量x中:
$$
x_{i}=\gamma(w_{i})\in R^{k}
$$
在本模型中,设定的文本总长度(token数量)为W=256000,显然嵌入空间χ为一个规模为k*W的矩阵。
对于具体的计划任务,PaLM-E必须能够在其生成的计划中引用对象。在简单的场景下,往往可以使用很简短的语言准确指向某一个物体对象,而在复杂场景下特别是具有较多相似物体的情况下则不能使用很简短的语言准确的指向某一个物体。针对这一问题,提出Entity Referrals 方法(类似取代号),用于解决物体描述非常长的情况下的编码问题:
在数据的最前面部分(输入提示prompt中)添加上对每个具体物体的描述(多模态标记),如:
1 | Object_1 is <obj_1>. ... Object_j is <obj_j>. |
其中 Object_1 和 Object_j 分别指代一个具体的物品,<obj_1> 和 <obj_j> 分别是对这两个物品的详细描述。
该方法使得PaLM-E能够在其生成的输出语句中通过 <obj_j> 形式的特殊标记来引用对象,后面的文本中再需要使用某个物品时就直接使用 Object_j 来代指,而不用再写出<obj_j> 的复杂描述。
不同传感器的数据映射
和文本相比,显然将不同传感器观测到的多种连续状态对齐到嵌入空间χ的难度要高很多,这里先根据传感器观测到的信息规格类型对其编码策略做简单的讨论:
状态值(状态向量)
最简单的情况——传感器的观测结果直接就是单个/多个状态值 【 e.g. 坐标、位置、大小、颜色…… 】
这种输入数据可以直接转为向量,可能还需要做一些归一化、对齐之类的操作;可以通过MLP(多层感知机,一个/多个全连接层)将该状态向量的维度进行转换,从而映射到嵌入空间χ中。
图像类数据
针对观测结果是图像类数据,直接使用比较成熟的 ViT(Vision Transformer) 模型(需事先进行图像分类的预训练)进行编码,将图像映射为多个token嵌入。
注意:ViT编码后的维数不一定和嵌入空间χ相同,还需要通过仿射变换ψ(参数需训练)将其投影至嵌入空间χ中。
待选择的编码方案:
- ViT-4B
- ViT-22B
- ViT + TL(TokenLearner)
TokenLearner:由于图像类数据维度是2维的,如果直接使用像素点进行编码的话形成的token序列会非常长,而transformer架构对长序列的运算速度非常慢。针对这个问题,Google提出了TokenLearner方法,该方法能够自适应的学习输入图片或视频中的重要区域,然后主要对这些重要区域进行tokenize编码,以达到只需要少量的token就足以表征所有的视觉特征的目的,既降低了计算复杂度,又提升了指标。
针对ViT + TL架构,对其从头开始进行端到端训练。
和文本输入不同,视觉输入之间往往不具有有意义的实体和关系。虽然ViT可以捕捉语义,但表示的结构类似于彼此相同的静态网格,而不是对象实例的集合,这意味着往往会把片中的一个对象划分成了多个部分,从而对与经过符号预训练的LLM接口以及解决需要与物理对象交互的具体推理都提出了挑战。针对这一问题,提出结构化编码器Object Centric Representations,在将视觉输入注入LLM之前将其分离成不同的对象,并在后续的划分过程中以图片中的每个对象为中心进行划分:
$$
x_{1:m}^{j}=\phi_{\mathrm{ViT}}(M_{j}\circ I)
$$
对于对象j,式中Mj为该对象实例的掩码,将其与原图像I相乘即可将该对象实例分割出来。
另一种不需要真实标注分割的方法是OSRT(Object Scene Representation Transformer):不依赖于关于对象的外部知识,而是通过架构中的归纳偏差以无监督的方式发现。基于SRT模型,OSRT通过新的视图合成任务来学习数据域内以3D为中心的神经场景表示。
注意:针对于连续的观察数据,每个对象总是会通过MLP编码器ϕ(需训练)映射为多个嵌入,再对齐到嵌入空间χ。
将以上的文本数据和感知数据映射到相同的嵌入空间χ后,还需要将感知数据嵌入到文本数据中:
将映射后的连续感知向量与普通嵌入文本标记交错,以形成LLM的前缀prefix,其中的每个向量 xi 由单词标记嵌入器 γ 或编码器 ϕi 构成:
$$
x_i=\left{\begin{array}{ll}\gamma\left(w_i\right)&\quad\mathrm{if}\text{ i a is text token, or}\\phi_j\left(O_j\right)_i&\quad\mathrm{if}\text{ i corresponds to observation}O_j\end{array}\right.
$$
显然单个观测(状态值/图像) Oj 通常被编码为多个嵌入向量。
可以在前缀中的不同位置交错不同的编码器 ϕi ,以组合来自不同观测空间的信息。以这种方式将连续信息注入LLM将重用其现有的位置编码。与其他VLM方法相比,这种嵌入没有插入固定位置,而是动态地放置在周围文本中。
模型架构
基本思想:将具身代理的传感器模态的连续输入融入语言模型,将连续的、具身的观察(如图像、位姿估计或其他传感器模态)添加到预训练语言模型的语言嵌入空间中,从而使语言模型本身能够为现实世界中的顺序决策做出更为基础的推断。
实现方式:基于预训练语言模型PaLM(decoder-only)【PaLM-E:PaLM + Embodied】,将连续状态观测编码为与输入文本维度相同的向量序列,作为语言标记的嵌入空间【以类似于语言标记的方式将连续信息注入到语言模型中,多模态的信息与文本可能是交错的】,并由基于Transformer的LLM的自注意力层以与纯文本相同的方式进行处理,在给定前缀提示词prefix prompt的情况下自回归地(autoregressive,用已生成的词来预测下一个位置的词)生成文本。
注意:该模型仅有文本输出,既可以是经典VQA任务中的回答,也可以表示机器人的决策/计划(任务分解)以控制机器人的底层执行行为(模型仅输出决策,套用现有的转化器将决策转化为底层行为);后者是本文研究的重点,但该模型在前者中也取得了SOTA的结果。
Decoder-only LLM
通过大型Transformer网络p_LM,在给定前面文本序列的情况下,预测概率p(各token的联合概率)最大的下一段文本(文本由一系列token ω_l表示):
$$
p\left(w_{1:L}\right)=\prod_{l=1}^Lp_{\mathrm{LM}}\left(w_l\mid w_{1:l-1}\right)
$$
Prefix-decoder-only LLM
在原有Decoder-only LLM架构基础上,在每条文本数据前添加一段前缀提示词prefix prompt(离散/连续)【通常包含任务描述或类似任务的文本示例】,以其为条件进行后续预测:
$$
p\left(w_{n+1:L}\mid w_{1:n}\right)=\prod_{l=n+1}^Lp_{\mathrm{LM}}\left(w_l\mid w_{1:l-1}\right)
$$
位置1~n:prefix prompt
位置n+1~L:输入的文本数据
训练时prefix prompt不参与loss计算
模型在机器人控制环中的输出
为了将模型的输出连接到机器人控制实例,主要有两种情况:
- 如果任务可以通过仅输出文本来完成(VQA/场景描述任务),则模型的输出被直接认为是任务的解决方案;
- 如果用于解决一个具体的计划或控制任务,它会生成一个文本来调节低级命令。
用简单的词汇表来执行低级技能的策略,模型输出的有效策略文本应为一系列低级技能的组合,对低级策略进行排序和控制。对于复杂的任务或指令,可能需要额外采用模型实现转换。这里假设低级策略可以直接操作物体对象的tokens,而不需要对于单个物体对象再进行拆分和转换。
PaLM-E实际上仅作为整个机器人控制中的上层决策模块,机器人控制环中还应有对应上层决策结果中的各低级策略的执行机构。
注意:模型必须根据训练数据和提示自行确定哪些技能可用,并且不使用其他机制来约束或过滤其输出。因此,模型训练时应放到整个机器人控制环中进行整体观测,根据执行结果动态调整上层决策模块PaLM-E生成的行为规划。
模型训练方法
训练数据集
训练数据集可以表示为:
$$
D=\left{\left(I_{1:u_{i}}^{i},w_{1:L_{i}}^{i},n_{i}\right)\right}_{i=1}^{N}
$$
其中:
- i:第i条数据
- L:一条数据的总长度【文本+连续状态编码后的结果】
- u:一条数据中有多少个通过传感器观测到的连续状态
- n:一条数据中 prefix prompt 部分的长度
- I:通过传感器观测到的连续状态
- ω:文本token
每条数据以文本为主体,基于文本中的特殊标记,用编码器的嵌入向量取代这些标记在原文本中的位置,从而把图像、连续状态都串成一条数据。显然每个图像经过嵌入层之后会被转化为多少个向量是固定的,所以只要给每个图像预留上对应个数的位置即可。
损失函数
在各非前缀tokens(n+1及之后位置)上平均的交叉熵损失(每条数据的前 ni 个位置是prefix prompt,不计算损失)
模型参数规模
将PaLM的不同预训练参数变体作为Decoder-only-LLM,通过编码器将连续观测值注入其中,这些编码器要么经过预训练,要么从头开始训练(见模态对齐部分)。
基于不同的PaLM预训练参数规模,得到了以下几种PaLM-E模型:
- PaLM-E-12B:8B PaLM + 4B ViT
- PaLM-E-84B:62B PaLM + 22B ViT
- PaLM-E-562B:540B PaLM + 22B ViT
模型冻结
本文中的整个模型系统可以分为三部分:
- 解码器Encoder,用 ϕ 表示;
- MLP(用于维度转换),用 ψ 表示;
- LLM,用 pLM 表示。
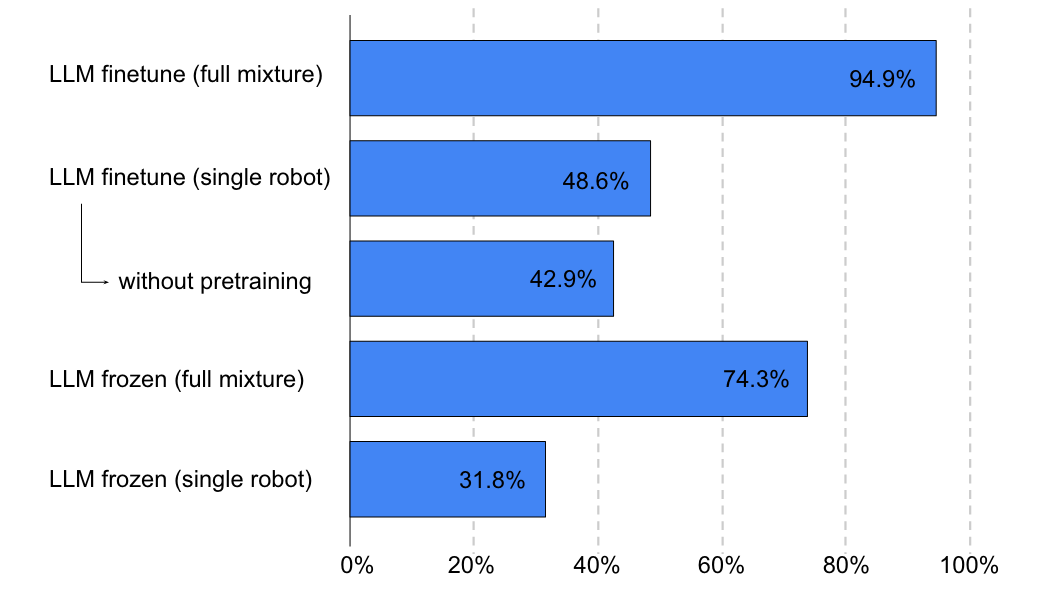
考虑如下事实:如果提供适当的提示,LLM可能会显示出令人印象深刻的推理能力。因此,在训练时不一定要这三部分的权重都同时更新,可以冻结其中的一部分(如LLM),只训练另外部分(如编码器)的权重。训练这种编码可以理解为一种与正常软提示相关的输入条件软提示形式。
本文中实际采用的三个策略为:
- 三个部分都同时进行训练;
- 冻结 LLM,训练编码器和MLP;
- 冻结 LLM 和 编码器,只训练MLP。
采用后两种策略的理由:LLM部分是基于PaLM模型,已经在大量数据上做过预训练的,其本身可能就已经有着非常强的能力;解码器也是类似的,比如采用ViT模型,那么该模型也是在大量图像数据上预训练过的;在上述三部分中只有 ψ 是随机初始化的,这部分模型必须要重新训练。
Experiments
测试演示详见论文主页:https://palm-e.github.io/
对比Baseline:VLM——PaLI(未在实例机器人数据上进行训练)、SayCan算法
机器人任务
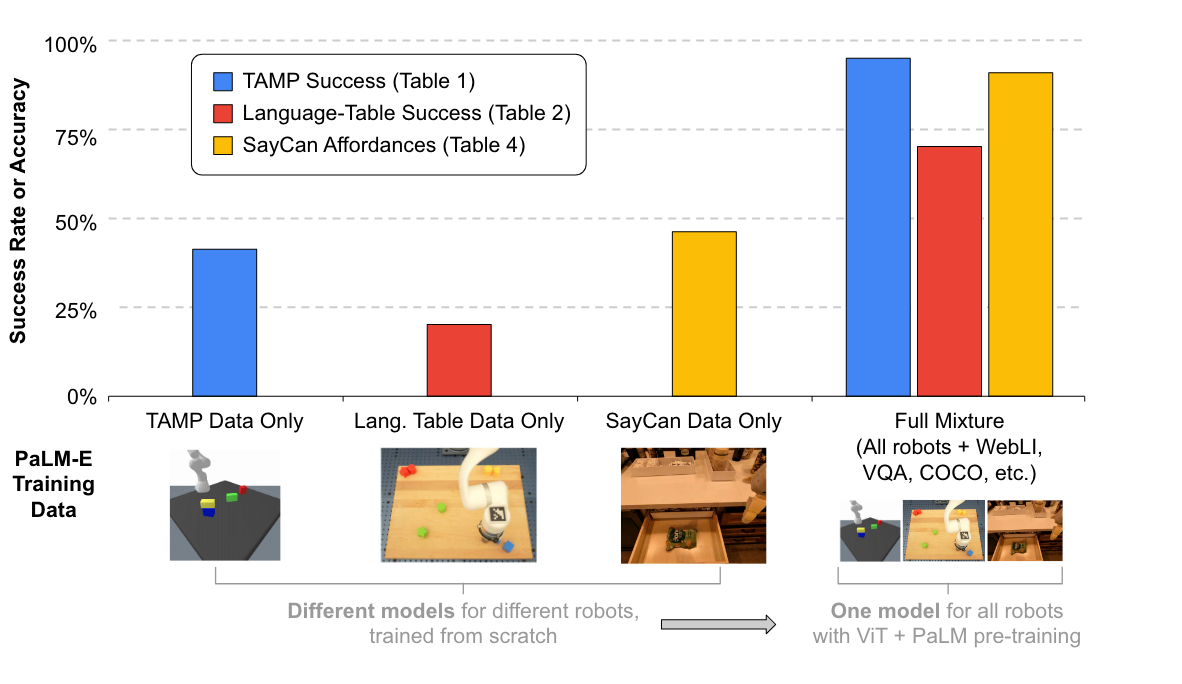
任务和运动规划Task and Motion Planning(TAMP)
四种 VQA 问题 + 两种plan问题:
四种 VQA 问题:
- q1 : 物品颜色问题。举例:给定一张图片。问:桌面上的物体是什么颜色?答:桌面上的物体是黄色。
- q2 : 物品-桌面位置关系问题。举例:给定一张图片。问:红色的物体在桌面的上方?左方?还是中心?答:红色的物体在桌面的中心。
- q3 : 物品-物品位置关系问题。举例:给定一张图片。问:黄色的物体是在蓝色的物体的下方吗?答:黄色的物体不在蓝色的物体的下方。
- q4 : 计划的可行性问题。举例:给定一张图片。问:先把蓝色的物体拿起来,然后把它堆放到黄色的物体上,然后能直接拿起黄色的物体吗?答:不能。
两种 plan 问题:
- p1 : 抓取问题。举例:给定一张图片。问:如何抓取绿色的物体?答:首先抓取黄色的物体并将其放到桌面上,然后抓取绿色的物体。
- p2 : 堆叠问题。举例:给定一张图片。问:如何将白色的物体堆放到红色的物体上方?答:首先抓取绿色的物体并将其放到桌面上,然后抓取白色的物体并将其堆放到红色的物体上方。

实验结果:
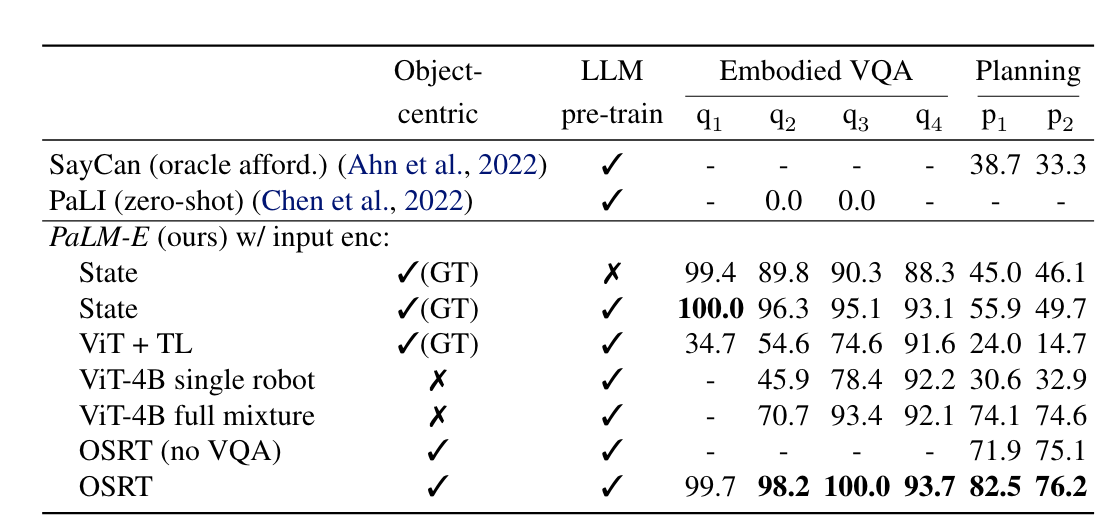
- 在训练比较少的情况下,使用预训练模型能够有较大的收益;
- ViT+TL 还是 ViT-4B 都不能够很好的处理2个plan任务,而加上跨任务(NLP+图像任务+机器人任务TAMP)的数据做训练之后(full mixture)在2个plan任务上的效果有了较大幅度的提升,这说明跨任务联合训练是有效的;
- 使用了 OSRT 作为编码器的效果较好;
- SayCan 和 PaLI 在仅使用1%的训练数据做训练的场景下,几乎没有能力解决相应的问题。
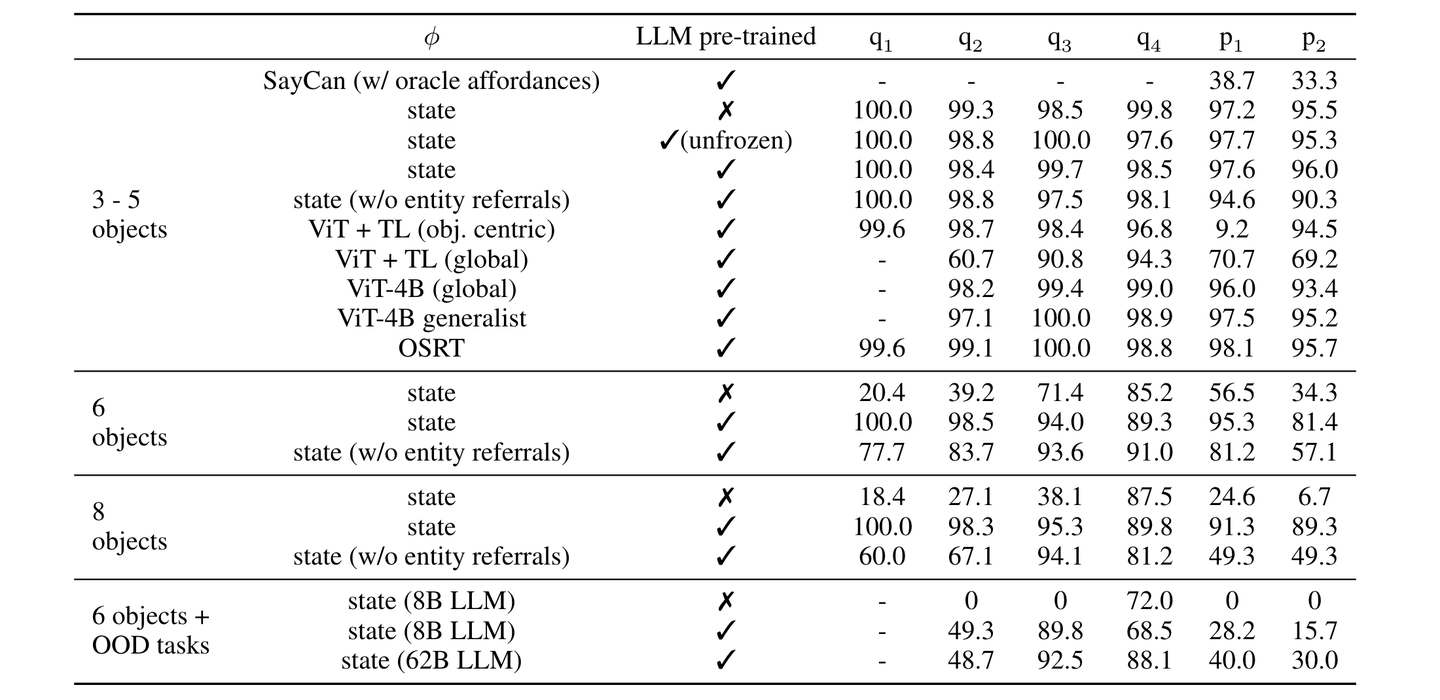
任务 TAMP 的每条训练数据中都是有3~5个物体,测试时还将每条数据中的物体数量增加到6个、甚至8个,以及还会增加训练数据中不存在的物体(out-of-distribution, OOD)。
- 当每条测试数据中的物体数量为3~5个时,各模型表现较为接近;
- 将每条测试数据中的物体数量增加到6个、甚至8个时,使用了预训练的 LLM 之后效果有着明显的提升;
- 在出现了训练数据中不存在的物体(OOD)时,不使用预训练 LLM 的模型完全无法处理该任务;使用了预训练 LLM 之后效果明显提升;并且将模型的尺寸由8B增大到62B之后也会有明显的提升。
桌面级操作Tabletop Manipulation
在桌面上摆一些不同颜色、不同形状的物体,机器人按照输入的命令用机械臂移动这些物体。

长期任务数据集:Language-Table
长期任务:模型无法通过一步完成该任务,而是需要每次自己生成策略、执行相应的action,然后观察外界环境,再次自己生成策略、执行相应的action,直到观察外界环境满足了任务要求。

数据集中包含3个任务类型:
- Task1 :将最靠近{某个方位,比如:右上角}的块,推到与它颜色相同的另一个块那里。
- Task2 :将所有的块按照颜色分组,并将每组推到桌面的四个角上。
- Task3 :将 左侧/右侧 的块推到一起,不要移动任何 右侧/左侧 的块。
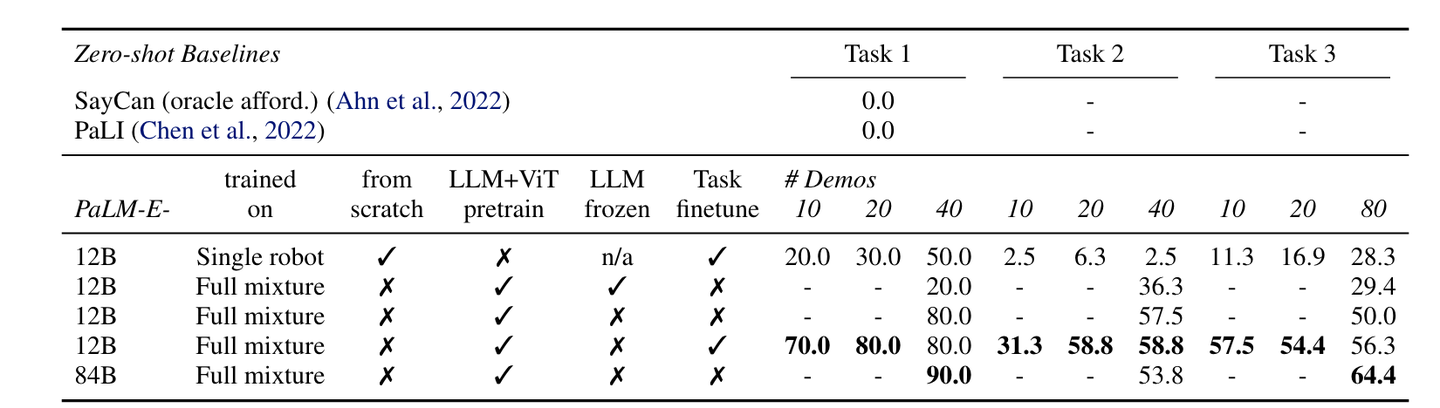
- 使用预训练模型后效果大幅提升;
- 增大模型参数规模后,在Task1和Task3这两个任务上有明显的提升,但是在Task2这个任务上有一些降低;
- SayCan 和 PaLI 这两个Baseline依然不具有解决该问题的能力。
移动操作Mobile Manipulation
移动操作环境就是机器人是可移动的,不再固定在桌面上。

测试任务:
- Affordance Prediction:给定一个物体/环境,以及一个操作,让模型预测该操作是否可在给定的物体/环境上执行。比如当环境中是红色块堆放在绿色块上方时,让模型预测能否抓取绿色块。模型预测结果应该是不能,因为必须先将红色块从绿色块上拿下来放到桌面上之后才能够抓取绿色块。
- Failure Detection: 对于机器人来说,当它执行完某一个操作之后,检测该操作是否执行成功也是很重要的。该任务就是检测执行的操作是否成功。
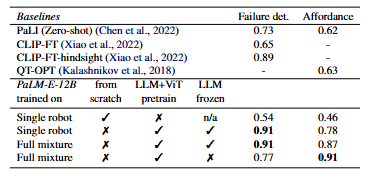
- 对于任务 Affordance Prediction:12B的 PaLM 预训练模型效果比 PaLI 和 QT-OPT 效果都要好;
- 对于任务 Failure Detection:12B的 PaLM 预训练模型效果明显超过了 PaLI 和 CLIP-FT;即使是使用了额外的数据做了优化的 CLIP-FT-hindsight 的效果也比 PaLM-E-12B 要略差一些。
视觉语言相关任务
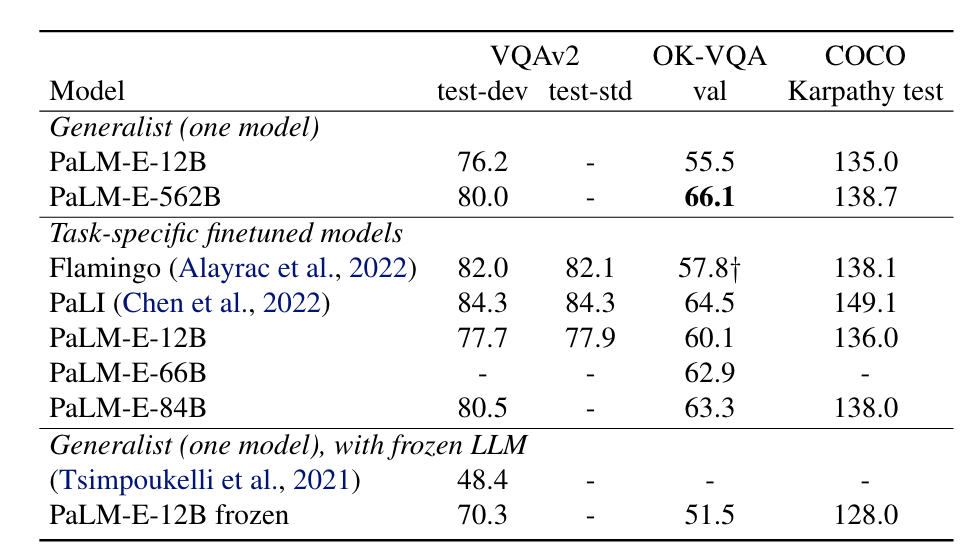
Visual-Language Tasks
总共3个任务,两个VQA任务:OK-VQA 任务和 VQAv2 任务,一个字幕任务:COCO captioning 任务。
Natural Language Processing Tasks
测试模型:
- PaLM-E-12B :使用 PaLM-8B 作为基座,加上 ViT-4B 得到的模型;
- PaLM-E-84B :使用 PaLM-62B 作为基座,加上 ViT-22B 得到的模型;
- PaLM-E-562B :使用 PaLM-540B 作为基座,加上 ViT-22B 得到的模型;
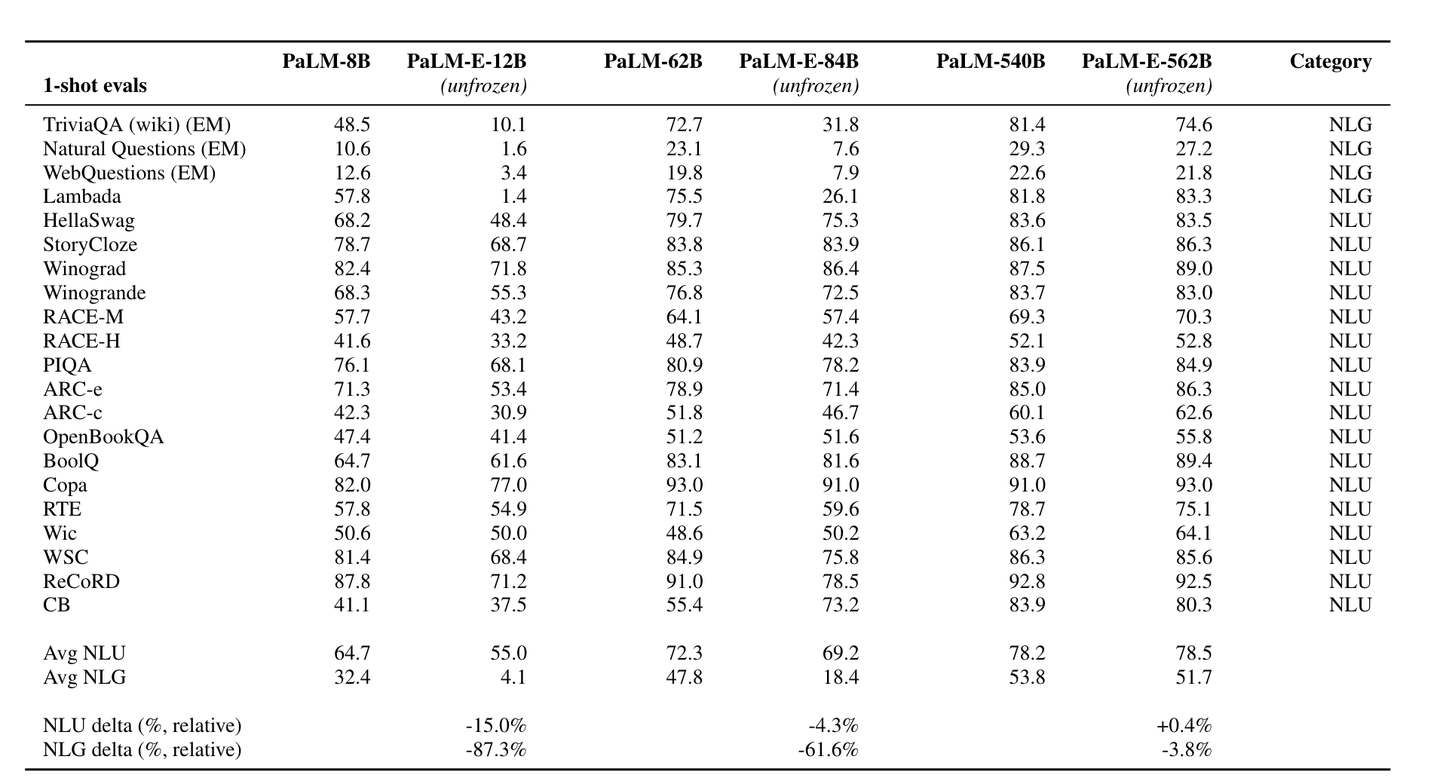
所有的 PaLM-E 模型都在机器人任务上做了微调,显然微调后的 PaLM-E 模型相较其对应的基本PaLM模型在NLP(NLG + NLU)任务上的效果均有所下降:
- PaLM-E-12B 相比于 PaLM-8B 在NLU和NLG任务上分别下降了 15.0% 和 87.3%;
- PaLM-E-84B 相比于 PaLM-62B 在NLU和NLG任务上分别下降了 4.3% 和 61.6%;
- PaLM-E-562B 相比于 PaLM-540B 在NLU任务上上升了 0.4%,在NLG任务上下降了 3.8%;
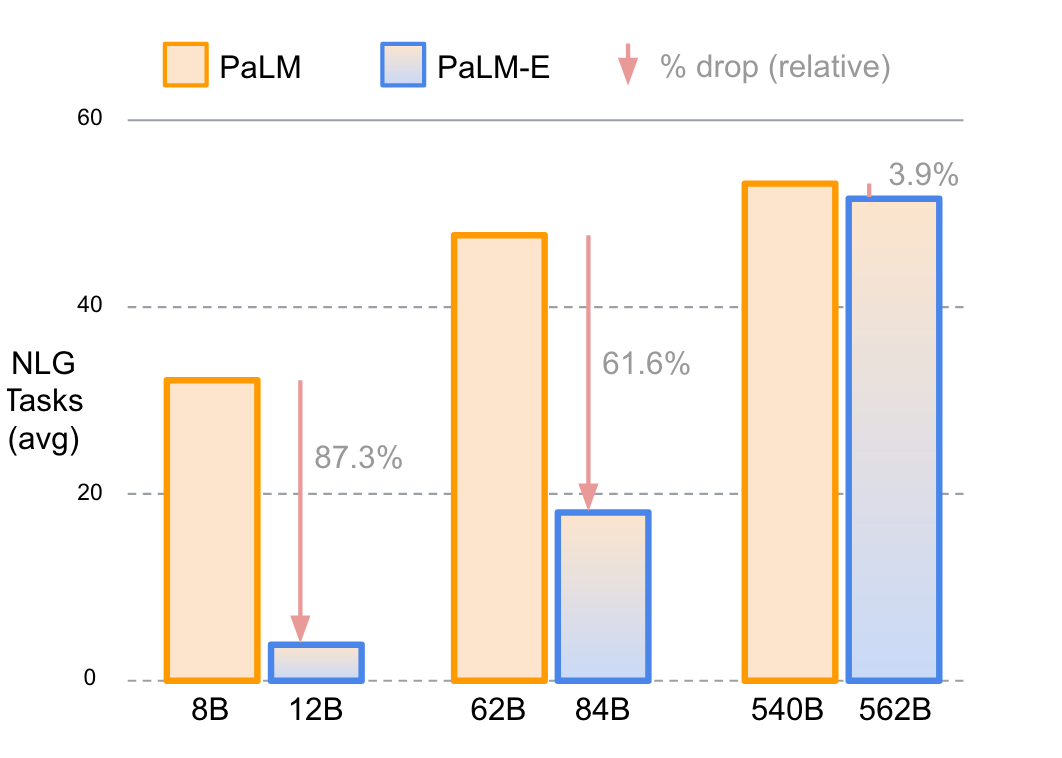
增加模型参数规模可以减少相应的 PaLM-E 模型与其继承的 PaLM 模型之间的灾难性遗忘。当模型特别大时,其所能储备信息的能力大幅增大,这样在新任务上做训练之后,就对之前的任务损耗较小。
PaLM-E:An Embodied Multimodal Language Model