A Survey on Vision-Language-Action Models for Embodied AI
Date:2025-3-4
原文链接:A Survey on Vision-Language-Action Models for Embodied AI
论文合集Github仓库:yueen-ma/Awesome-VLA
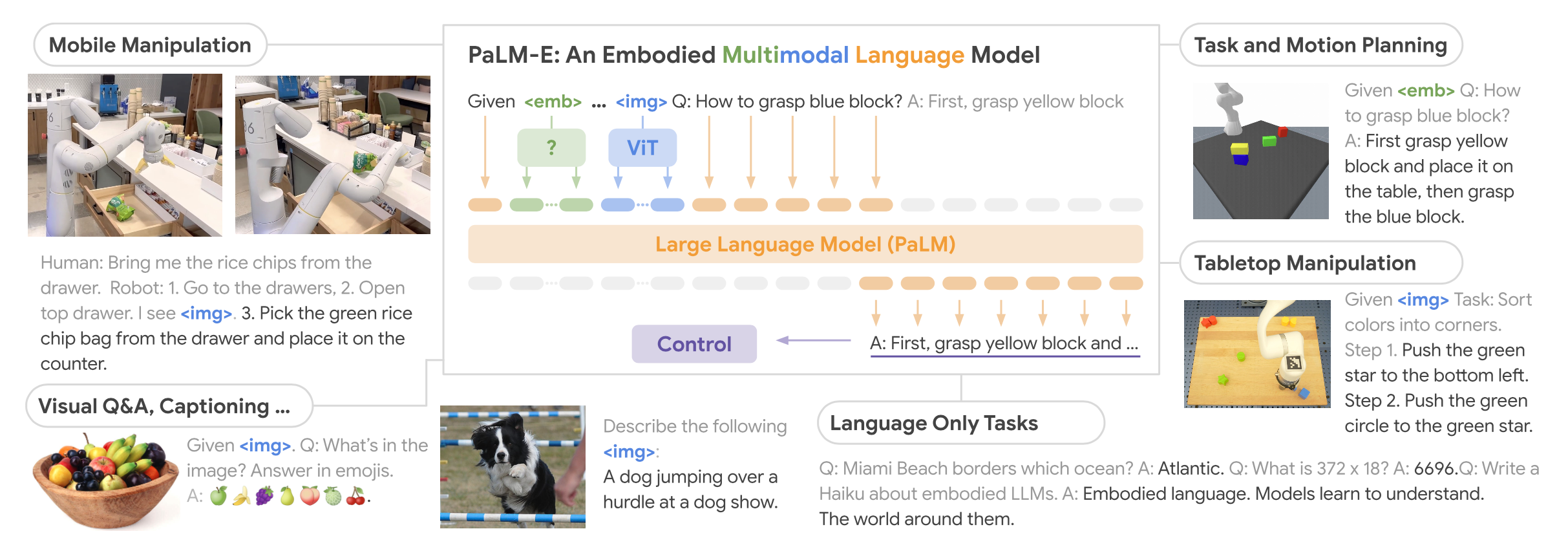
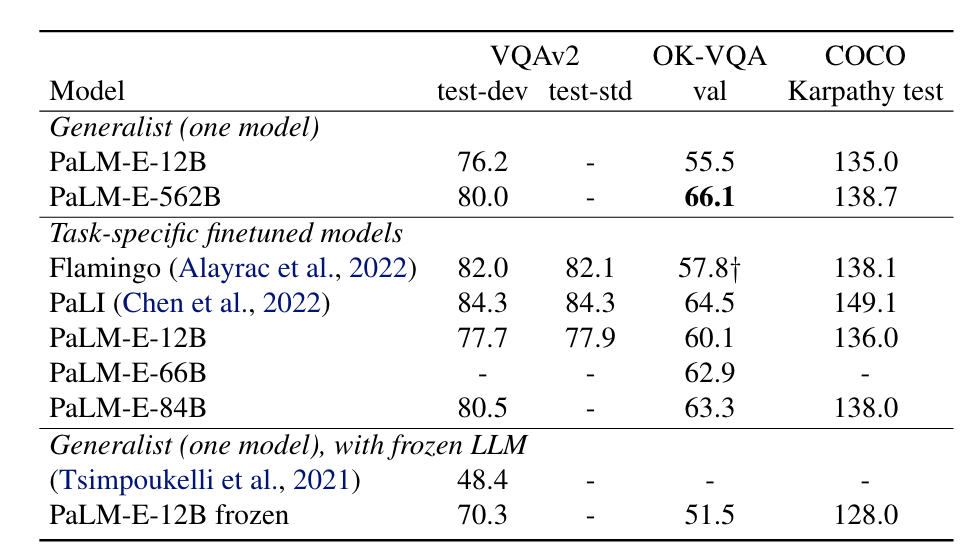
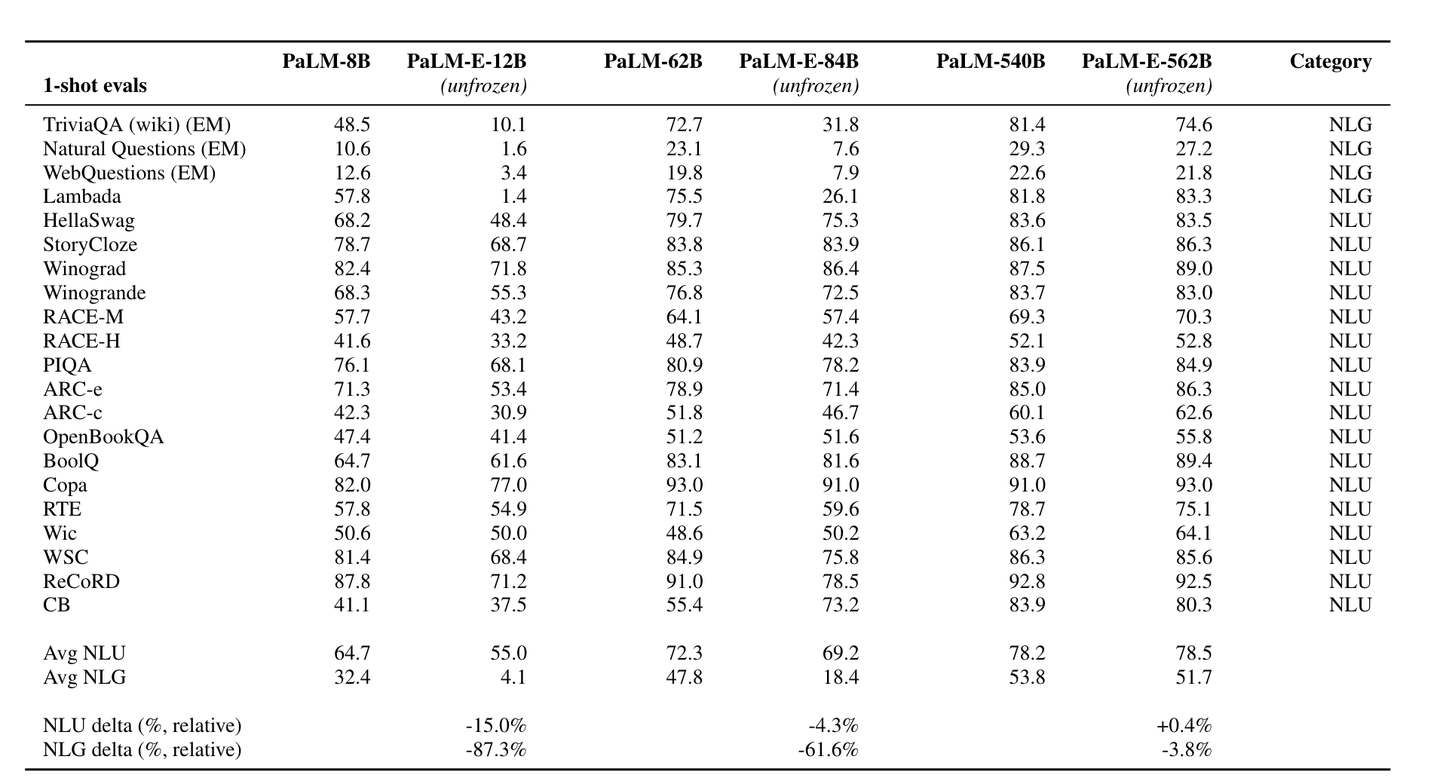
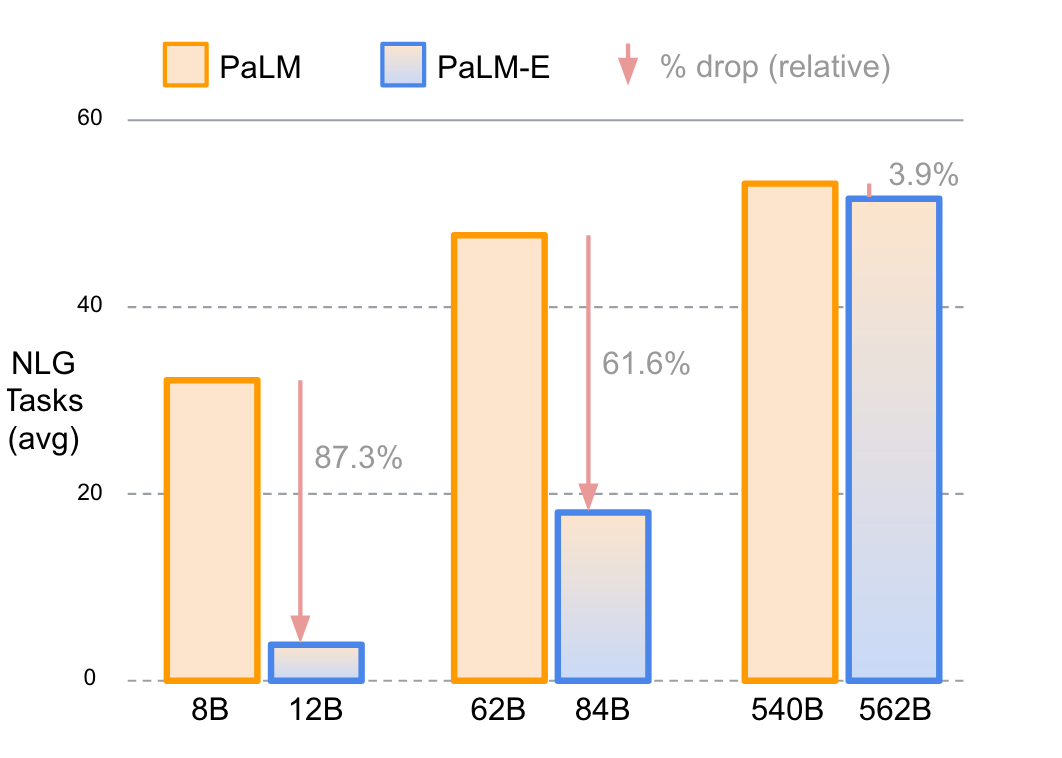
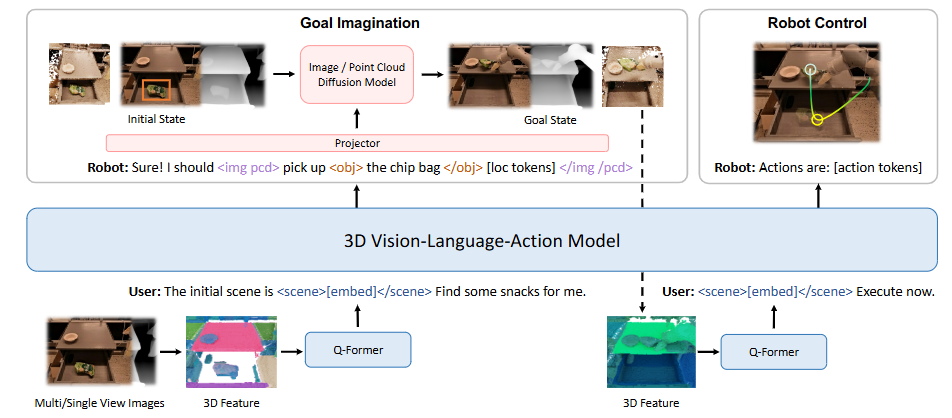
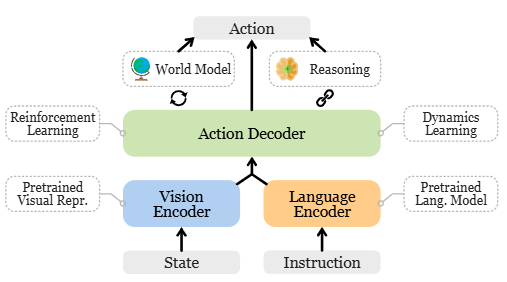
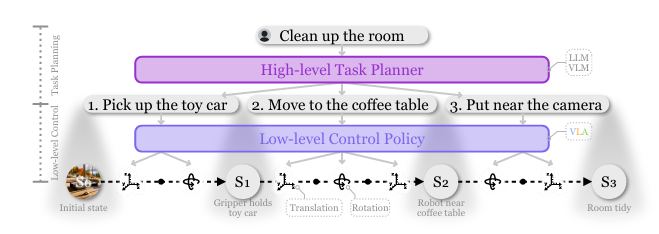
在LLM和VLM的成功基础上,RT-2首次提出了视觉-语言-动作模型 (Vision-Language-Action models,VLA)这一概念,通过利用其生成动作的独特能力来解决具身智能中基于语言指令的机器人任务。在基于语言指令的机器人任务中,策略必须具备理解语言指令、视觉感知环境并生成适当动作的能力,这需要 VLA 的多模态能力。
VLA Model
文章按照三个主要研究方向,列举了具有代表性的VLA模型:
- 预训练:侧重于 VLA 的各个组件,如视觉编码器或动力学模型;
- 机器人控制策略:开发擅长预测低级行动的控制策略,根据指定的语言命令和感知环境执行低级动作;
- 高级任务规划器:将长期任务分解为一系列可由控制策略执行的子任务,从而指导 VLA 遵循更通用的用户指示。
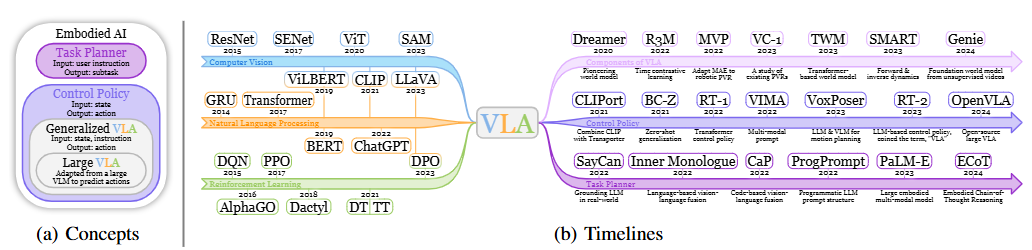
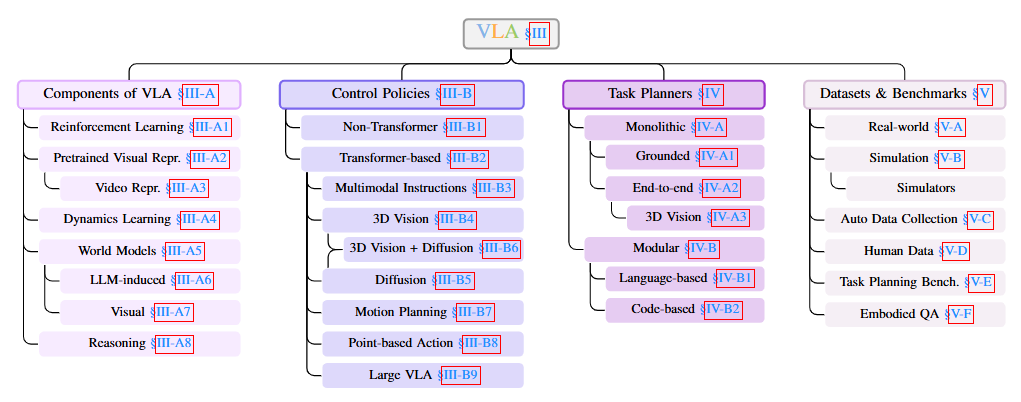
预训练
强化学习
强化学习以状态-动作-奖励序列为特征,这与序列建模问题的结构一致,因此非常适合 Transformer 模型,也是许多最新 VLA 模型的基础。
- 开创性工作:决策变换器(DT)、轨迹变换器(TT),Gato 进一步将这种范式扩展到多模态/任务/具身体设置。
- 来自人类反馈的强化学习 (RLHF) 已成为 LLM 的重要训练要素:SEED 利用 RLHF 和基于技能的强化学习来解决机器人学习中长距离任务的稀疏奖励问题;Reflexion 提出了一种新的语言强化学习框架,用语言反馈取代了 RL 模型中的权重更新。
Pretrained Visual Representations(PVR)
视觉编码器的有效性直接影响策略的性能,因为它提供有关目标类别、位置和环境可供性的关键信息。因此,许多方法都致力于对视觉编码器进行预训练,以提高PVR的质量。

视频表示
视频是简单的图像序列,可以通过连接每帧的通常 PVR 来表示。然而,它们的多视角特性使上述之外的各种独特表示技术成为可能。
- 时间对比学习和 MAE;
- 利用NeRF 从视频中提取丰富的 3D 信息用于机器人学习,如 F3RM 和 3D-LLM 。
- 3D 高斯展开 (3D-GS) 方法可以通过基于物理的生成动力学模拟来变形(PhysGaussian),也可以用作 3D 表示(UniGS )
[Integrating Historical Learning and Multi-View Attention with Hierarchical Feature Fusion for Robotic Manipulation](https://www.mdpi.com/2313-7673/9/11/712#:~:text=In response to these limitations%2C we propose a,information%2C hierarchical feature fusion%2C and multi-view attention mechanisms.)一文中提出了一种基于互信息的多视角注意力机制,将多个视角的图像信息进行混合,并有选择地突出最具信息性的视角。
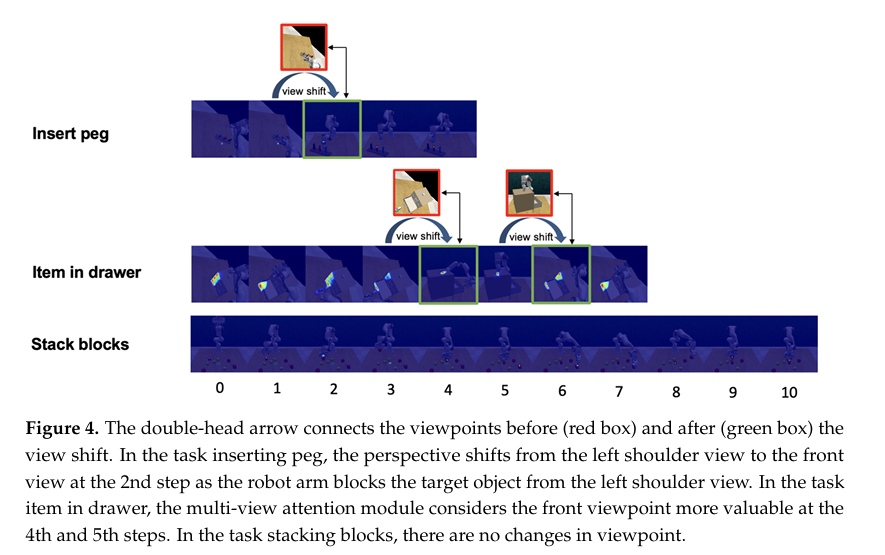
此外,许多视频包含音频,这可以为机器人策略提供重要提示。
动态学习
动态学习包含旨在使模型了解正向或逆向动态的目标。正向动态涉及预测给定动作导致的后续状态,而逆向动态则涉及确定从先前状态过渡到已知后续状态所需的动作。
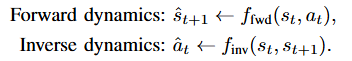
虽然正向动态模型与世界模型密切相关,不过这里特别关注利用动态学习作为辅助任务来提高主要机器人任务性能的工作。

世界模型
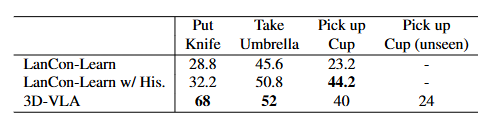
编码有关世界的常识性知识,并预测给定动作的未来状态:
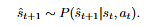
它支持对具身代理进行基于模型的控制和规划,因为它们可以在执行任何实际动作之前在虚构空间中搜索最佳动作序列。此外,可以从明确生成未来状态的图像或视频的视觉世界模型中采样新的具身示例。
尽管正向动态学习也试图预测下一个状态,但它通常被视为预训练任务或辅助损失,以增强基于 RL-Transformer 的动作解码器以用于主要机器人任务,而不是作为一个独立的模块。
- LLM-induced World Models:LLM中包含大量关于世界的常识性知识,因此许多方法想利用这些知识来改进VLA;
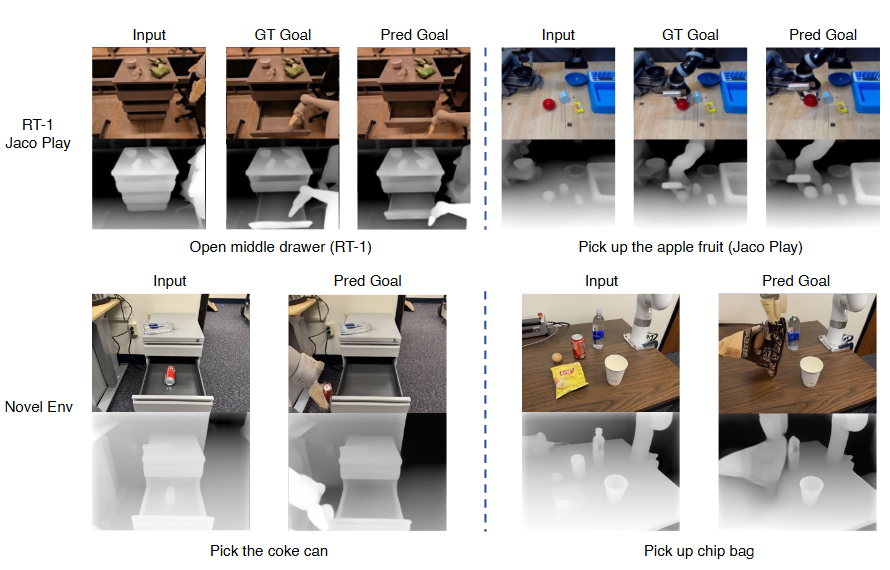
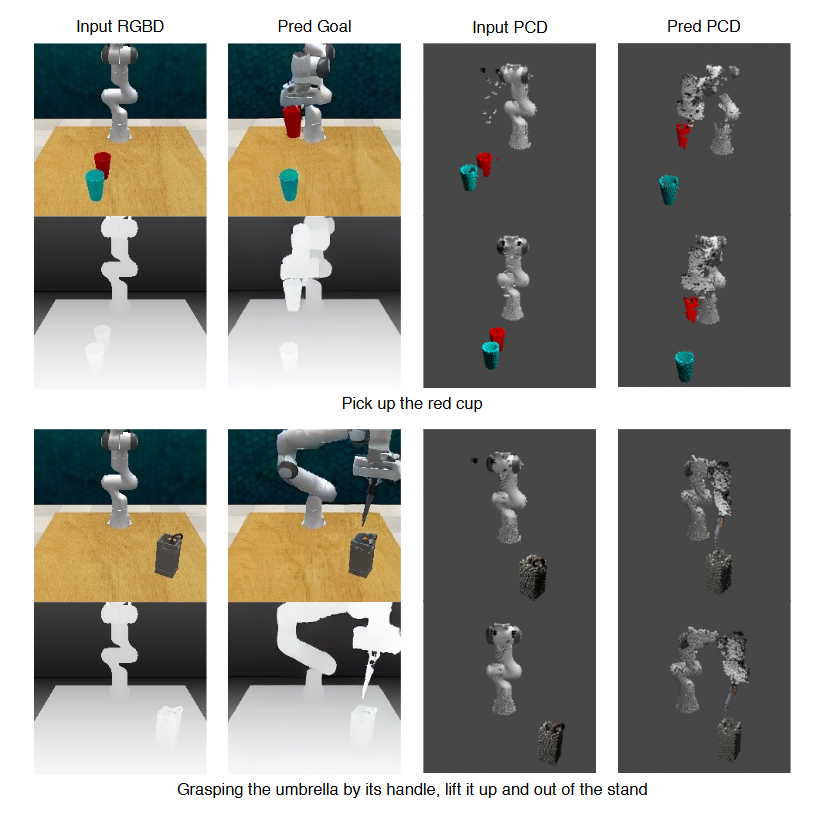
- Visual World Models:生成未来状态的图像、视频或 3D 场景以使得世界模型与物理世界更紧密地保持一致,可进一步用于生成新的轨迹。
Reasoning
思维链 (CoT) 方法证明推理(Reasoning)已成为 LLM 的一项关键能力,因此想要探索如何利用 CoT 推理来完善决策过程。
总结
- 预训练的视觉表征强调了视觉编码器的重要性,因为视觉观察在感知环境的当前状态方面起着至关重要的作用。因此,它为整个模型的性能设定了上限。在 VLA 中,一般视觉模型使用机器人或人类数据进行预训练,以增强其在目标检测、可供性图提取甚至视觉语言对齐等任务中的能力,这些任务对于机器人任务至关重要。
- 相比之下,动态学习侧重于理解状态之间的转换。这不仅涉及将视觉观测映射到良好的状态表征,还涉及理解不同的动作如何导致不同的状态,反之亦然。现有的动态学习方法通常旨在使用简单的掩码建模或重新排序目标来捕捉状态和动作之间的关系。
- 另一方面,世界模型旨在完全模拟世界的动态,使机器人模型能够根据当前状态将状态推广到未来的多个步骤,从而更好地预测最佳动作。因此,虽然世界模型更受欢迎,但实现起来也更具挑战性。
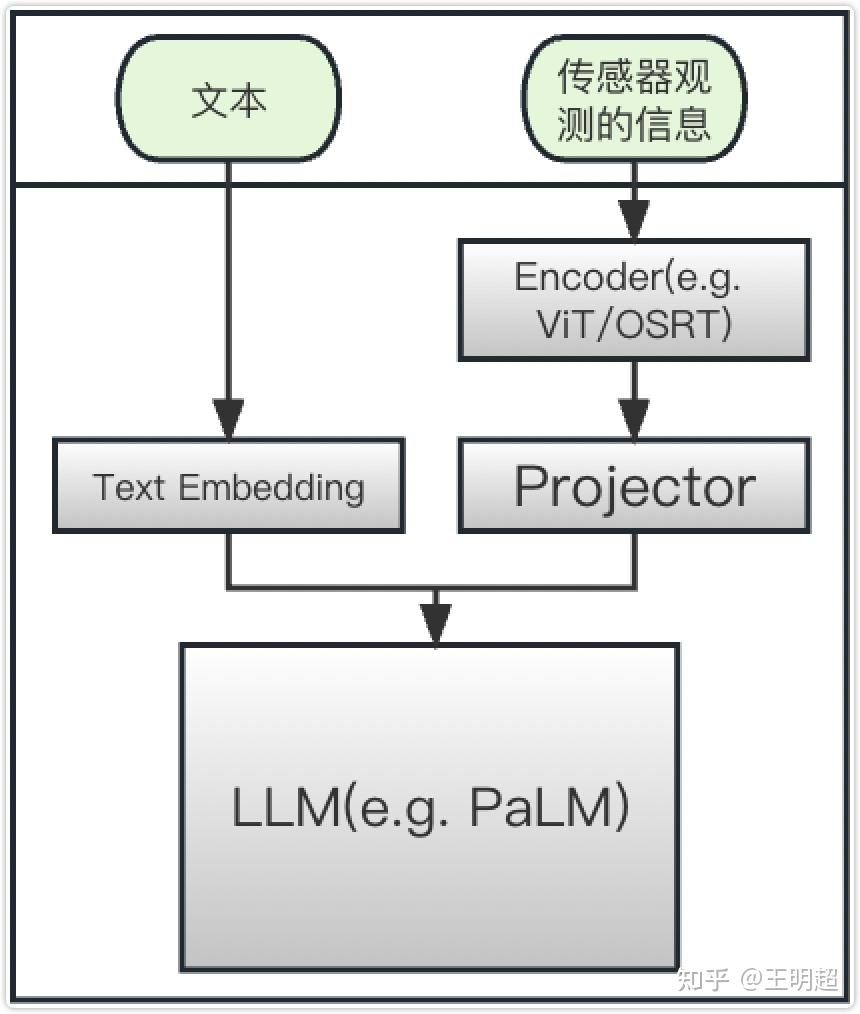
底层控制策略
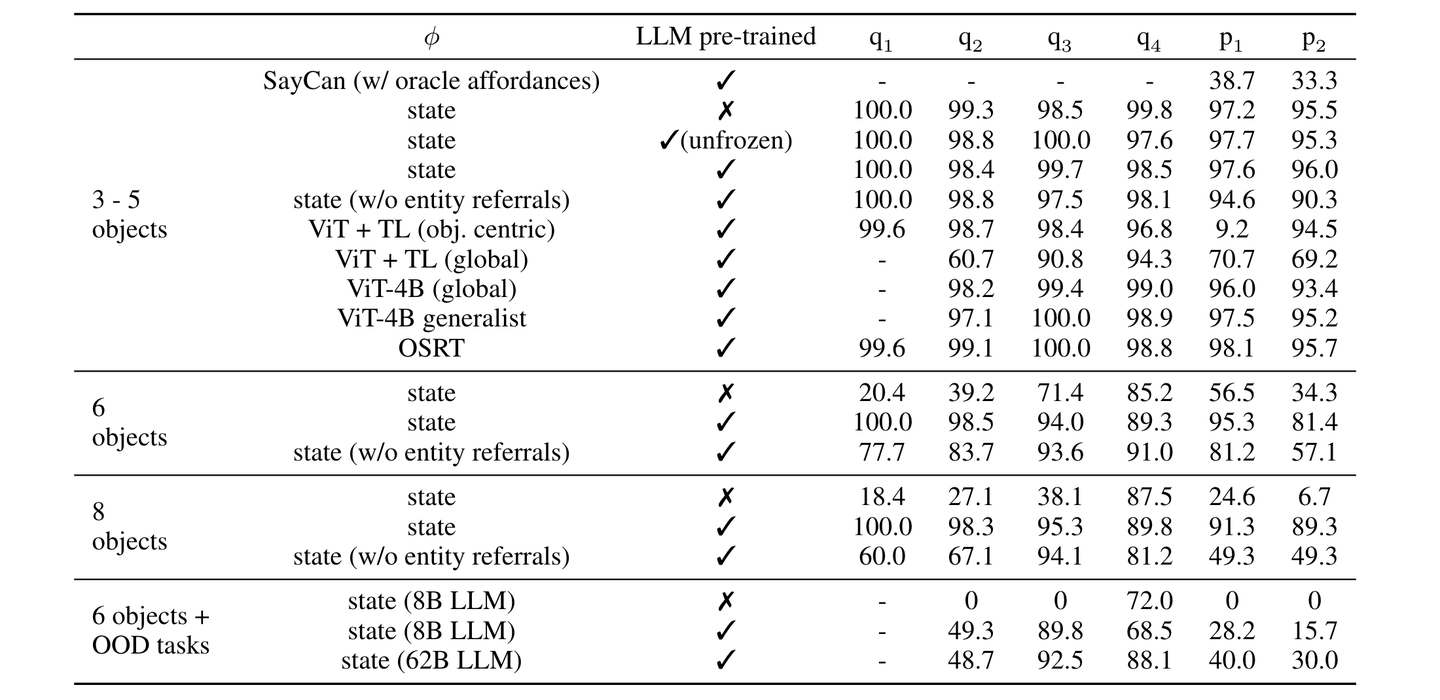
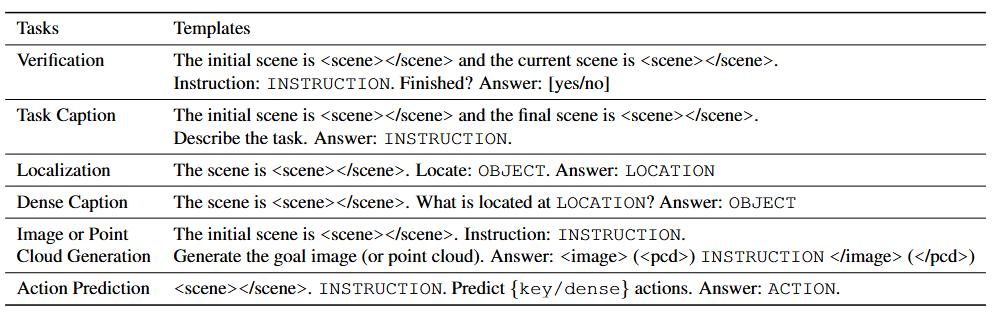
将动作解码器与感知模块(如视觉编码器和语言编码器)集成,形成一个策略网络来在模拟或真实环境中执行指令。控制策略网络的多样性在于编码器/解码器类型的选择以及集成这些模块所采用的策略。语言指令控制策略包括以下类型:非 Transformer、基于 Transformer和基于 LLM。一些其他控制策略处理多模态指令和目标状态指令。
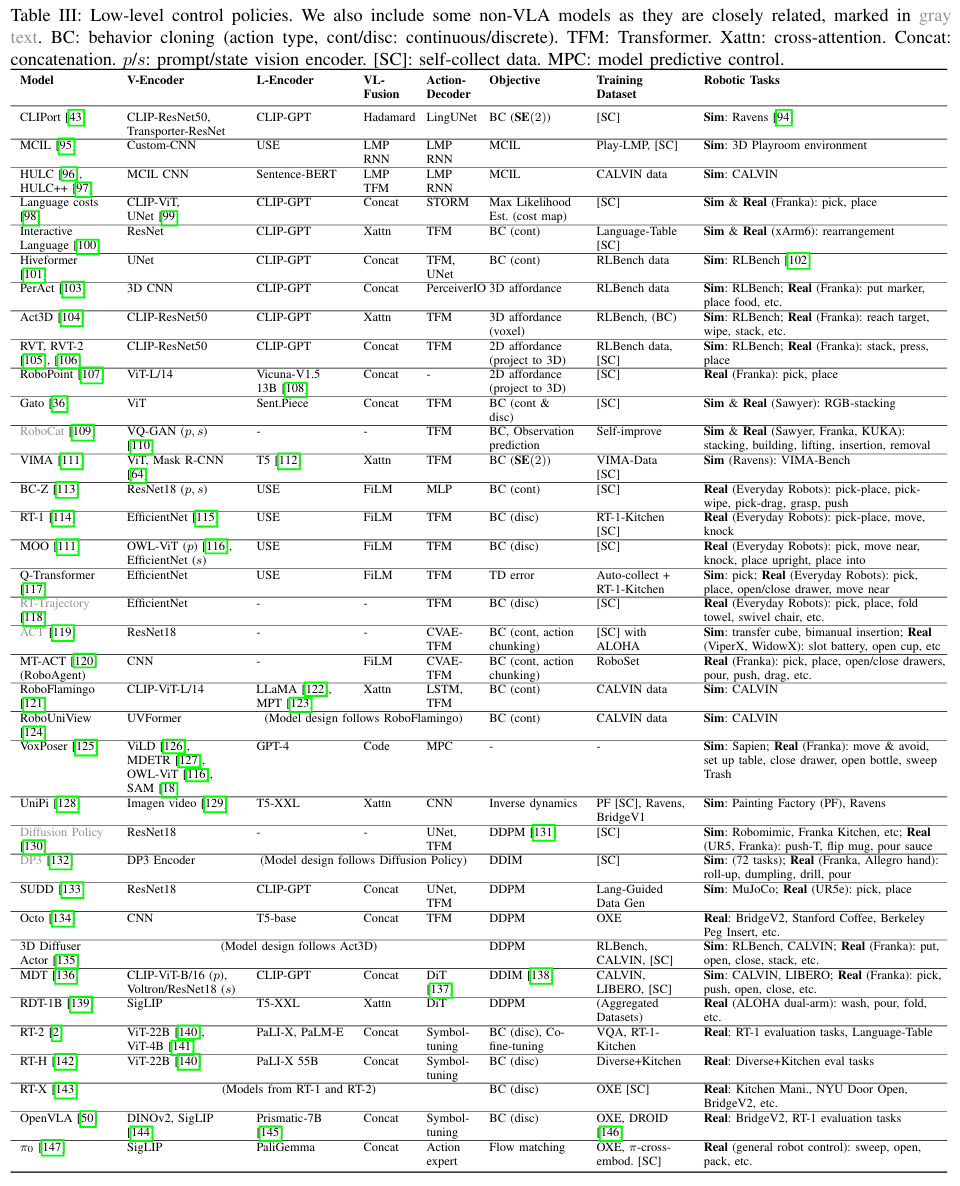
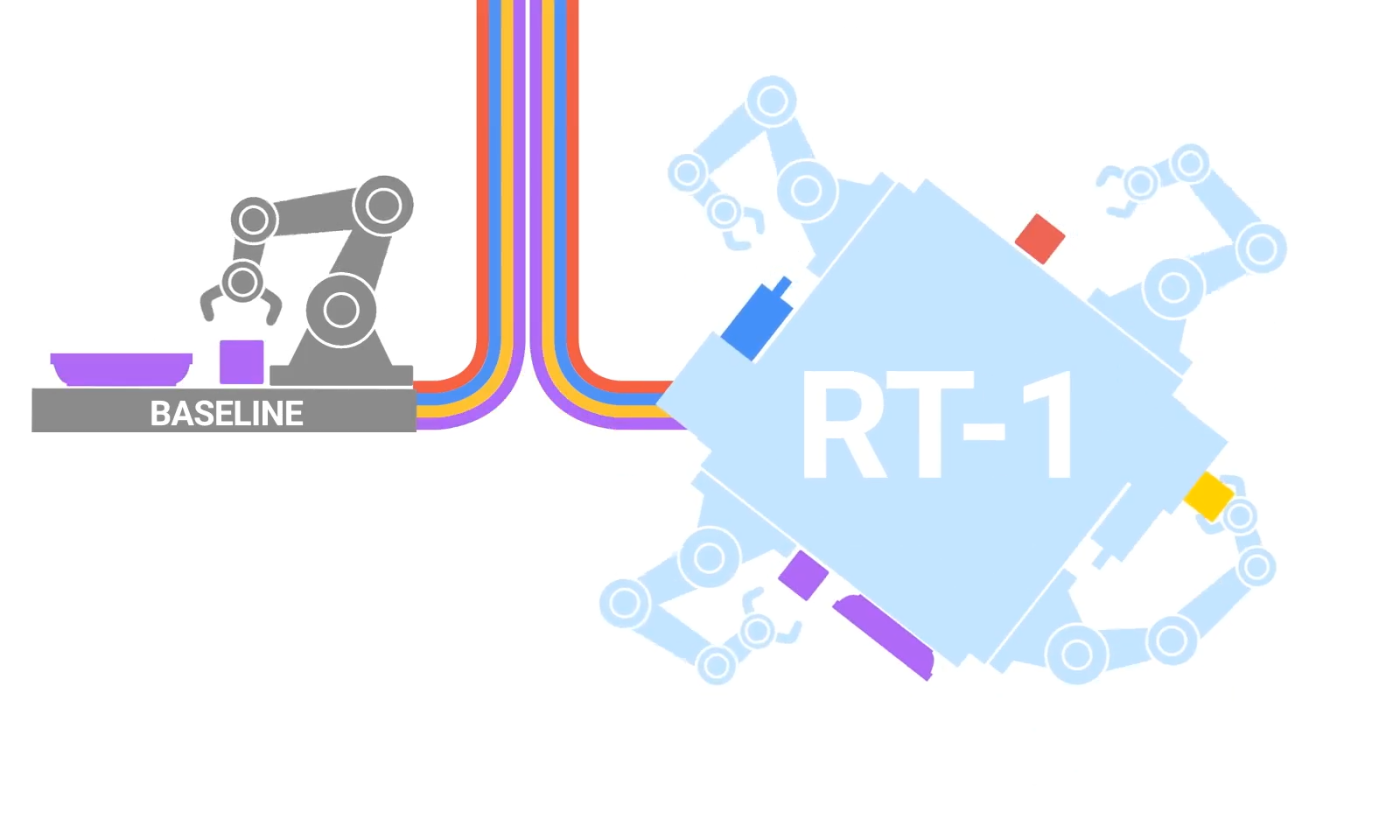
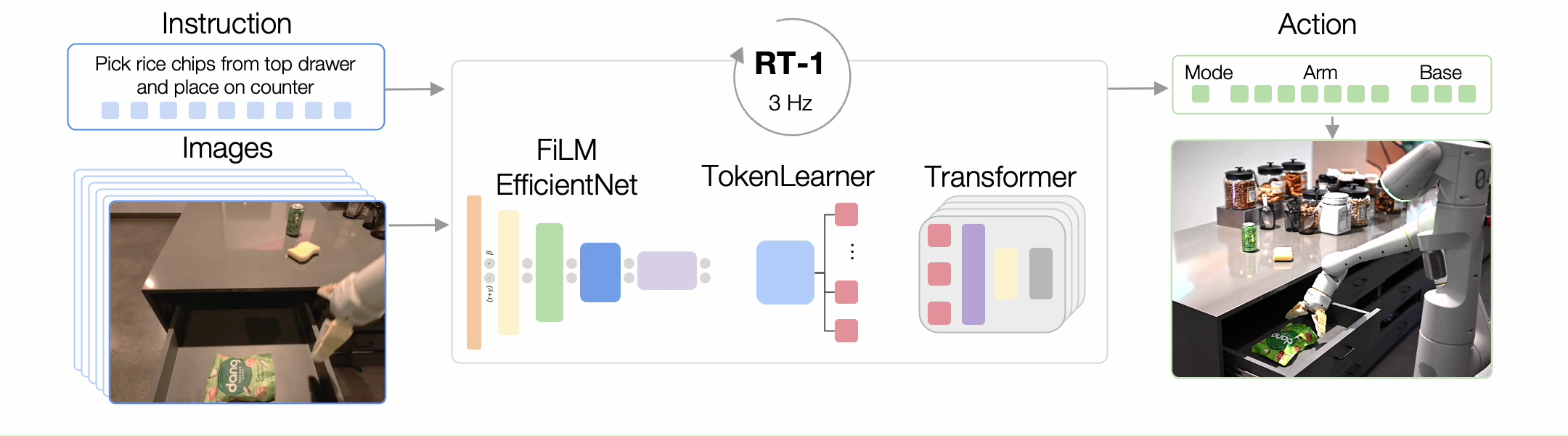
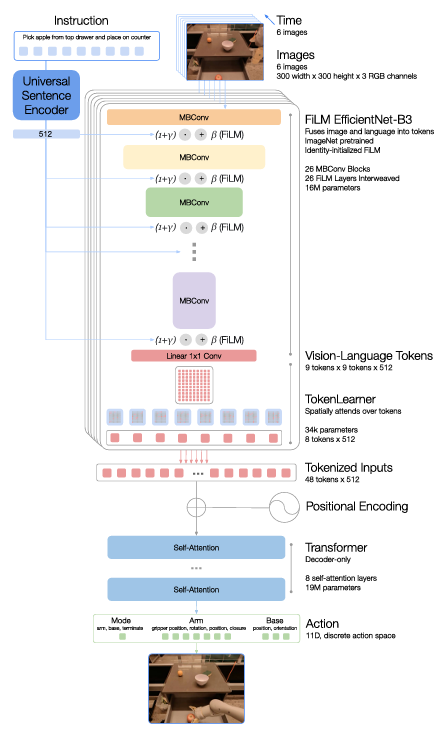
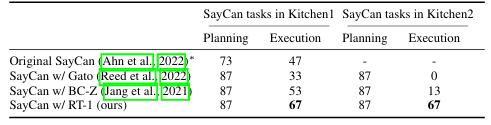
各种 VLA 架构探索了融合视觉和语言输入的不同方法,包括交叉注意、FiLM 和连接,RT-1 中使用了 FiLM,因此其后续工作也继承了这一机制。虽然交叉注意在较小的模型规模下可以提供更好的性能,但连接更易于实现,并且可以在较大的模型上实现相当的结果 [41]。
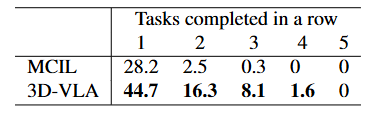
如图所示,三种最常见的低级控制策略架构的特点,是其视觉-语言融合方法。一些 Transformer 动作解码器利用交叉注意来条件化指令。在基于 RT-1 的模型中,FiLM 层用于早期融合语言和视觉。连接是 Transformer 动作解码器中视觉-语言融合的主流方法。
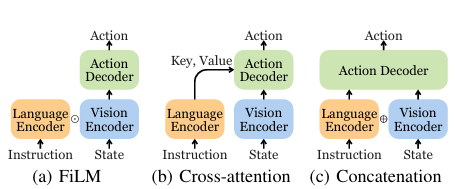
大多数低级控制策略会预测末端执行器姿势的动作,同时抽象出使用逆运动学控制各个关节运动的运动规划模块。虽然这种抽象有助于更好地推广到不同的实施例,但它也对灵活性施加了限制。行为克隆 (BC) 目标用于模仿学习,针对不同的动作类型有不同的变体。
基于扩散的策略利用了计算机视觉领域中扩散模型的成功。其中,扩散策略是最早利用扩散进行动作生成的策略之一。SUDD为扩散策略添加了语言条件支持。Octo采用模块化设计,以适应各种类型的提示和观察。与常见的行为克隆策略相比,扩散策略在处理多模态动作分布和高维动作空间方面表现出优势。
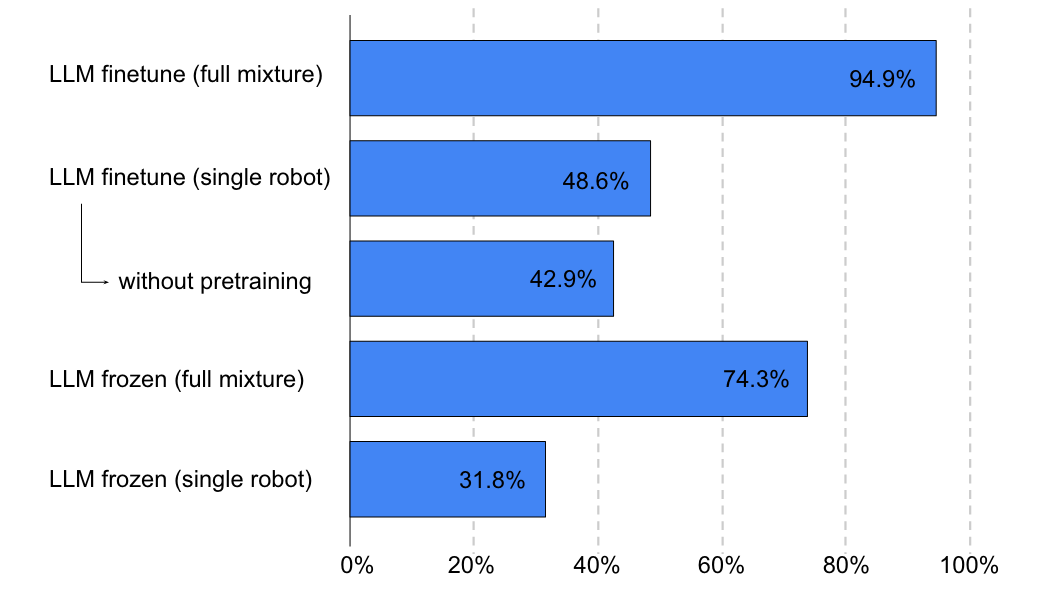
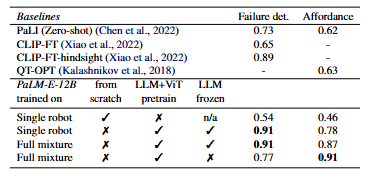
虽然基于 LLM 的控制策略可以大大增强指令跟随能力,因为 LLM 可以更好地解析用户意图,但人们担心其训练成本和部署速度。尤其是推理速度慢会严重影响动态环境中的性能,因为在 LLM 推理期间可能会发生环境变化。
高级任务规划器
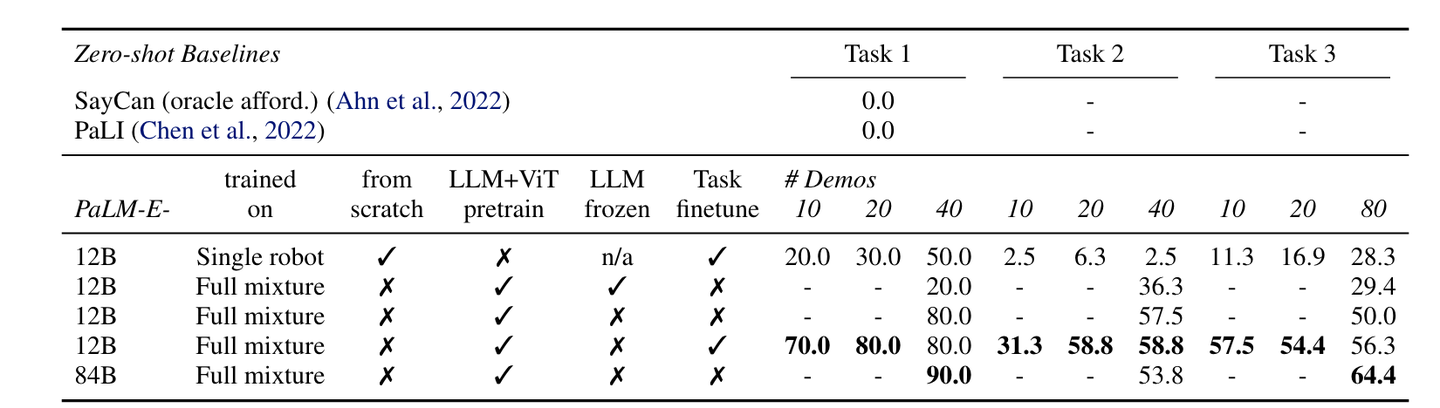
许多高级任务规划器都是在 LLM 之上构建的。虽然以端到端方式将多模态模块集成到 LLM 中是直观的,但使用多模态数据进行训练可能成本高昂。因此,一些任务规划器更喜欢使用语言或代码作为交换多模态信息的媒介,因为它们可以由 LLM 原生处理。
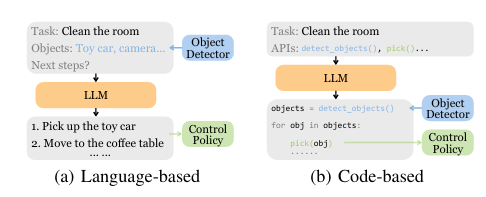

虽然像 SayCan 这样的端到端任务规划器与低级控制策略具有类似的架构,并且可以针对特定任务进行优化,但由于 LLM 和ViT组合的模型规模很大,它们的训练成本可能过高。基于语言的任务规划器具有与现有语言条件控制策略无缝集成的优势。然而,它们通常需要微调或对齐方法来将生成的规划映射到低级控制策略的可执行语言指令。另一方面,基于代码的任务规划器利用 LLM 的编程能力来连接感知和动作模块。这种方法不需要额外的训练,但其性能可能会受到现有模型能力的限制。
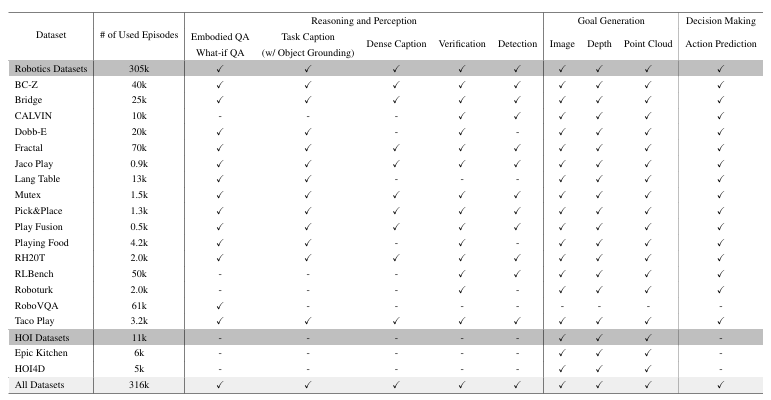
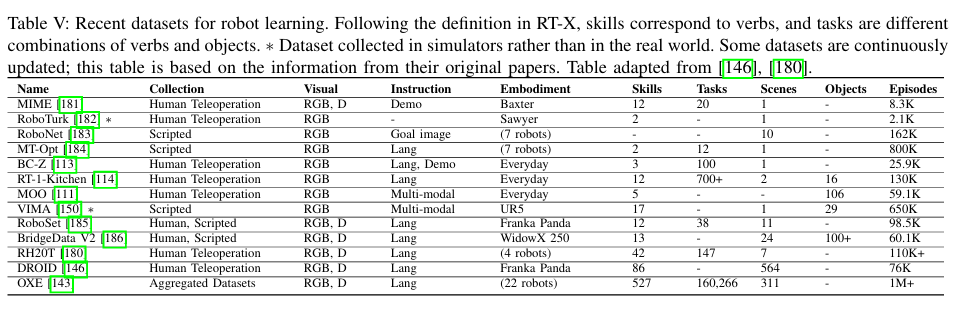
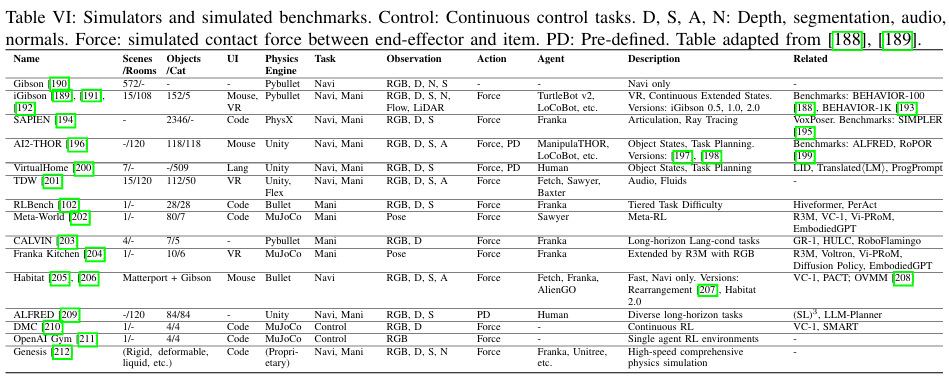
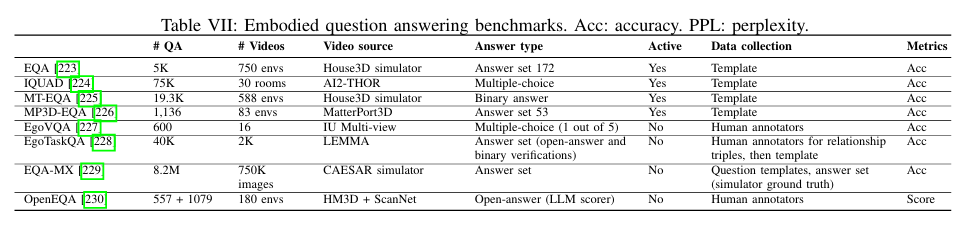
Datasets, Simulators and Benchmarks
Challenges and Future Directions
- 机器人数据稀缺:获取足够的现实世界机器人数据仍然是一个重大障碍,收集此类数据耗时且耗费资源,而仅依靠模拟数据会加剧模拟与现实之间的差距问题。
- 运动规划:当前的运动规划模块通常缺乏解决各种环境中的复杂性所需的灵活性,这种限制妨碍了机器人与工具有效交互、在复杂环境中导航和执行高精度操作等的能力。
- 实时响应:许多机器人应用需要实时决策和动作执行才能满足操作要求,VLA 模型应设计为响应迅速、延迟最小。
- 多模态集成:VLA 必须处理和集成来自多种模态的信息,包括视觉、语言和动作,虽然在这方面已经取得了重大进展,但实现这些模态的最佳集成仍然是一个持续的挑战。
- 泛化到未见的场景:一个真正多功能的机器人系统应该能够在各种未见的场景中理解和执行自然语言指令。
- 鲁棒性:能够稳定的适应指令、环境、对象和实施方案的变化。
- 长远任务执行:成功执行此类任务需要机器人在较长的时间范围内规划和执行一系列低级动作,虽然当前的高级任务规划器已经取得了初步成功,但它们在许多情况下仍然存在不足。
- 基础模型:在机器人任务中探索 VLA 的基础模型仍然是未知领域,这主要是由于机器人技术中遇到的多种具体化、环境和任务。
- Benchmark:尽管存在许多用于评估低级控制策略 VLA 的基准,但它们在评估的技能方面往往存在很大差异;此外,这些基准中包含的对象和场景通常受到模拟器可以提供的内容的限制。
- 安全注意事项:安全是机器人技术的重中之重,因为机器人直接与现实世界互动;确保机器人系统的安全需要将现实世界的常识和复杂的推理融入到其开发和部署过程中,这涉及到整合强大的安全机制、风险评估框架和人机交互协议。
- 伦理和社会影响:机器人的部署始终引发各种伦理、法律和社会问题,这些包括与隐私、安全、工作流失、决策偏见以及对社会规范和人际关系的影响相关的风险。