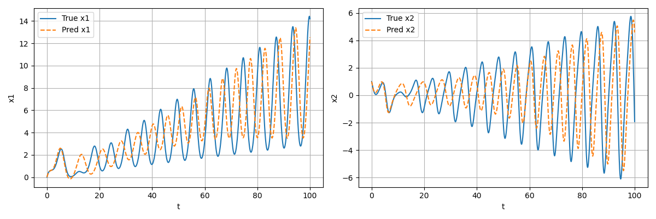
#均值和标准差对 params=[(0,1),(0,2),(3,1)] d2l.plot(x,[normal(x,mu,sigma)for mu,sigma in params],xlabel='x',ylabel='p(x)',figsize=(4.5,2.5),legend=[f'mean{mu},std{sigma}'for mu,sigma in params])
3.2 线性回归的从零开始实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
%matplotlib inline import random import torch from d2l import torch as d2l
#定义优化算法——小批量随机梯度下降 #lr:学习速率(梯度下降步长);batch_size:批量大小 defsgd(params,lr,batch_size): #@save #小批量随机梯度下降 with torch.no_grad(): for param in params: param-=lr*param.grad/batch_size param.grad.zero_() #训练 #设置超参数 lr=0.03#学习率 num_epochs=3#迭代周期个数 net=linreg loss=squared_loss
for epoch inrange(num_epochs): for X,y in data_iter(batch_size,features,labels): l=loss(net(X,w,b),y)#X和y的小批量损失 #因为l的形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,并以此计算关于[w,b]的梯度 l.sum().backward() sgd([w,b],lr,batch_size)#使用参数的梯度以更新参数 with torch.no_grad(): train_l=loss(net(features,w,b),labels) print(f'epoch{epoch+1},loss{float(train_l.mean()):f}')
num_epochs=3#迭代周期个数 for epoch inrange(num_epochs): for X,y in data_iter: l=loss(net(X),y)#X和y的小批量损失 trainer.zero_grad() l.backward() trainer.step()#使用参数的梯度以更新参数 l=loss(net(features),labels) print(f'epoch{epoch+1},loss{l:f}')
#在数字标签索引与文本名称之间进行转换 defget_fashion_mnist_labels(labels): #@save #返回Fashion-MNIST数据集的文本标签 text_labels=['t-shirt','trouser','pullover','dress','coat','sandal','shirt','sneaker','bag','ankle boot'] return [text_labels[int(i)] for i in labels]
#可视化样本 defshow_images(imgs,num_rows,num_cols,titles=None,scale=1.5): #@save #绘制图像列表 figsize=(num_cols*scale,num_rows*scale) _,axes=d2l.plt.subplots(num_rows,num_cols,figsize=figsize) axes=axes.flatten() for i,(ax,img) inenumerate(zip(axes,imgs)): if torch.is_tensor(img): #图片张量 ax.imshow(img.numpy()) else: #PIL图片 ax.imshow(img) ax.axes.get_xaxis().set_visible(False) ax.axes.get_yaxis().set_visible(False) if titles: ax.set_title(titles[i]) return axes
X = torch.tensor(inputs.to_numpy(dtype=float)) y = torch.tensor(outputs.to_numpy(dtype=float)) #X,y = torch.tensor(inputs.values),torch.tensor(outputs.values) X, y
d2l.set_figsize((6,4.5)) for i inrange(6): d2l.plt.plot(estimates[:,i].numpy(),label=("P(die="+str(i+1)+")")) d2l.plt.axhline(y=0.167,color='black',linestyle='dashed') d2l.plt.gca().set_xlabel('Groups of experiments') d2l.plt.gca().set_ylabel('Estimated probability') d2l.plt.legend();
Help on built-in function ones in module torch:
ones(...)
ones(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) -> Tensor
Returns a tensor filled with the scalar value `1`, with the shape defined
by the variable argument :attr:`size`.
Args:
size (int...): a sequence of integers defining the shape of the output tensor.
Can be a variable number of arguments or a collection like a list or tuple.
Keyword arguments:
out (Tensor, optional): the output tensor.
dtype (:class:`torch.dtype`, optional): the desired data type of returned tensor.
Default: if ``None``, uses a global default (see :func:`torch.set_default_tensor_type`).
layout (:class:`torch.layout`, optional): the desired layout of returned Tensor.
Default: ``torch.strided``.
device (:class:`torch.device`, optional): the desired device of returned tensor.
Default: if ``None``, uses the current device for the default tensor type
(see :func:`torch.set_default_tensor_type`). :attr:`device` will be the CPU
for CPU tensor types and the current CUDA device for CUDA tensor types.
requires_grad (bool, optional): If autograd should record operations on the
returned tensor. Default: ``False``.
Example::
>>> torch.ones(2, 3)
tensor([[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> torch.ones(5)
tensor([ 1., 1., 1., 1., 1.])
1
torch.ones(4)
tensor([1., 1., 1., 1.])
1
?
1
list?
1
help(list)
Help on class list in module builtins:
class list(object)
| list(iterable=(), /)
|
| Built-in mutable sequence.
|
| If no argument is given, the constructor creates a new empty list.
| The argument must be an iterable if specified.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __delitem__(self, key, /)
| Delete self[key].
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(...)
| x.__getitem__(y) <==> x[y]
|
| __gt__(self, value, /)
| Return self>value.
|
| __iadd__(self, value, /)
| Implement self+=value.
|
| __imul__(self, value, /)
| Implement self*=value.
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mul__(self, value, /)
| Return self*value.
|
| __ne__(self, value, /)
| Return self!=value.
|
| __repr__(self, /)
| Return repr(self).
|
| __reversed__(self, /)
| Return a reverse iterator over the list.
|
| __rmul__(self, value, /)
| Return value*self.
|
| __setitem__(self, key, value, /)
| Set self[key] to value.
|
| __sizeof__(self, /)
| Return the size of the list in memory, in bytes.
|
| append(self, object, /)
| Append object to the end of the list.
|
| clear(self, /)
| Remove all items from list.
|
| copy(self, /)
| Return a shallow copy of the list.
|
| count(self, value, /)
| Return number of occurrences of value.
|
| extend(self, iterable, /)
| Extend list by appending elements from the iterable.
|
| index(self, value, start=0, stop=9223372036854775807, /)
| Return first index of value.
|
| Raises ValueError if the value is not present.
|
| insert(self, index, object, /)
| Insert object before index.
|
| pop(self, index=-1, /)
| Remove and return item at index (default last).
|
| Raises IndexError if list is empty or index is out of range.
|
| remove(self, value, /)
| Remove first occurrence of value.
|
| Raises ValueError if the value is not present.
|
| reverse(self, /)
| Reverse *IN PLACE*.
|
| sort(self, /, *, key=None, reverse=False)
| Sort the list in ascending order and return None.
|
| The sort is in-place (i.e. the list itself is modified) and stable (i.e. the
| order of two equal elements is maintained).
|
| If a key function is given, apply it once to each list item and sort them,
| ascending or descending, according to their function values.
|
| The reverse flag can be set to sort in descending order.
|
| ----------------------------------------------------------------------
| Class methods defined here:
|
| __class_getitem__(...) from builtins.type
| See PEP 585
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __hash__ = None