选题背景与意义
微分方程是数学中一个重要且广泛应用的领域,涉及到描述变化和相互关系的方程。它是一种包含导数或微分的方程,常用于自然现象建模以及解决科学和工程领域中的问题。微分方程研究是数学中的一个重要分支,涵盖了广泛的领域和应用。通过研究微分方程,我们可以理解和预测自然现象的行为,以及解决科学和工程中的实际问题。同时,微分方程的研究也促进了数学的发展和数学工具在其他学科中的应用。
常微分方程被广泛应用于物理、生物、化学、经济学等各个领域。在许多情况下,观测数据是已知的,而其中隐含的微分方程仍然难以捉摸。因此,数据驱动的常微分方程(或动力系统)发现和反演是一个重要的研究方向。
微分方程反演问题是相对于微分方程的求解而言的:
- 微分方程的求解通常是一个正向问题,即给定初始条件,求解关于未知函数的方程;
- 微分方程反演问题是指根据已知的结果,推导出产生这些结果的微分方程,是从结果向方程的逆向推导和反演。
在数学上,微分方程的反演问题具有一系列的数学挑战和困难:
- 反问题的病态性:微小扰动在反问题的输出中会导致较大的误差,因此需要稳定性分析和正则化方法来解决数值计算中的误差;
- 存在非唯一解情况:需要利用先验信息、约束条件和经验知识等来进行问题的约束和规定,以得到合理的解。
微分方程反演问题研究在数学理论和实际应用中具有重要意义。通过解决微分方程的反演问题,我们可以从有限的观测数据中重建和推断未知的边界条件、初始条件或未知函数,从而深入理解系统的行为和性质,并提供科学、工程和医学等领域的相关应用。
随着计算机技术的发展,数值计算和机器学习在微分方程反演问题研究中的应用也呈现出迅猛发展的趋势。传统的微分方程推断方法依赖于领域专家的知识和经验,而机器学习方法,如神经网络、深度学习和遗传算法等,可以自动从大量数据中学习模式和关系,从而更准确地推断出微分方程模型。如今我们可以获取到大规模的、高维度的数据集,这为从数据中推断微分方程提供了更多的信息和挑战。而传统的模型推断方法在处理大数据集时可能受到维度灾难和计算复杂度的限制。机器学习的强大计算能力和自适应建模能力为解决这些问题提供了新的思路。
利用机器学习从数据中反演微分方程的方法可以分为两个方面:
- 在模型选择方面,机器学习可以通过自动搜索和学习合适的微分方程模型,利用测度函数或结构特征来评估不同模型的性能,并选择最适合数据的微分方程模型;
- 在参数估计方面,机器学习可以利用大数据集中的样本来优化微分方程模型的参数,以最小化模型与实际数据之间的误差。
利用机器学习从数据中反演微分方程是微分方程和机器学习交叉领域的重要研究方向。它利用机器学习的能力和大数据的优势,可以更准确地建模和预测复杂的动力学系统,推进科学研究和实际应用的发展。
针对常微分方程,目前常用的反演方法有如下几种:
- 高斯过程:将高斯过程置于状态函数之上,然后通过最大化边际对数似然性从数据中推断参数,这种方法适用于解决高维问题,但是对系统的形式有限制,并且仅用于估计系统的参数。
- 符号回归:创建并更正与观测数据相对应的符号模型,为控制函数提供更具表现力的函数形式,但缺点是对于大型系统来说计算成本高,并可能容易过拟合。
- 稀疏回归:找到候选基函数的稀疏组合来近似控制函数,其系数由最小二乘法或贝叶斯回归确定。这种方法提供系统的明确形式,不需要太多先验知识,但是依靠适当的候选函数;对于没有简单或稀疏表示的复杂动力系统来说可能是低效的。
- 统计学习:通过最小化经验误差来学习系统在某个假设空间中的相互作用核,避免维度诅咒,可以发现非常高维度的系统,但是仅适用于具有交互作用的核函数的动力系统。
- 物理信息神经网络(PINN):一种新的深度学习方法,用于解决非线性偏微分方程的正问题和反问题。通过在前馈神经网络中嵌入由偏微分方程描述的物理信息,在不需要标签数据的情况下,将 PINN 训练为偏微分方程的近似解的代理模型。受此启发,进一步发展出了多步神经网络LMNets,这本质上是使用给定相点上的流映射提供的信息来反演动力系统种的未知控制函数f的一种逆过程。
在数值分析中,发展高阶方法是许多应用中的一个重要课题。传统上,在求解动力系统时,高阶离散化技术,如线性多步法和龙格-库塔方法已经得到了发展。近年来,线性多步法也被用于动力系统的发现。随着使用深度学习的发现取得令人满意的进展,对它在动力系统发现的理论理解也在进一步发展。
基于以上所陈述的微分方程反演问题的研究现状,针对无显式方程的非线性系统这一在真实物理世界中更为广泛且常见的情形,我们希望基于高阶离散化技术线性多步法,结合多步神经网络LMNets这一深度学习方法,拟合和反演出数据背后的动力学物理规律。
算法框架与原理
研究对象——常微分方程(组)
首先明确我们的研究对象——常微分方程:
$$
\begin{aligned}&\frac{dx(t)}{dt}=f(x(t),t),\&x(t_{0})=x_{0}\end{aligned}
$$
上述式子是一个最简单的二维常微分方程示例,其中x(t) ∈ R是关于时间t的函数,函数关系由一个微分方程刻画,且给出了一定的初值条件以唯一确定函数x的表达式,从而能够真实地刻画物理过程随时间变化的发展情况。
事实上大多数时候我们需要观测的物理量远远不止x这一个,因此为了后续更容易推广到高维情形(后续无特别说明,均围绕自治常微分方程展开讨论),我们将上述的非自治常微分方程转化为向量化的自治常微分方程:
$$
\begin{aligned}&\frac{d\boldsymbol{u}(t)}{dt}=\hat{f}(\boldsymbol{u}(t)),\&\boldsymbol{u}(t_{0})=\boldsymbol{u}{0}\end{aligned}
$$
其中:
$$
u=(x,y)\in\mathbb{R}^{D+1},\hat{f}=(f,1)^{T},u{0}=(x_{0},t_{0})^{T}
$$
在反演问题中,已知在若干时刻节点t_1、t_2、…、t_n的解x的数据,我们一般不会希望直接解出x(t)的表达式,而是通过确定光滑函数f,从而利用给定的数据反演出微分方程。这样的传统是从简单的反演情形推广并沿用的,因为比起得到一个精确的函数表达式,我们更希望探究这个表达式背后的物理规律,而这往往离不开微分方程,因此保留微分方程的形式具有一定的必要性。
多步神经网络
线性多步法是用于微分方程数值求解的常用方法。传统上,它们用于求解给定常微分方程的解,可以称为微分方程的正问题。但线性多步法也可以用于反演给定解的原微分方程,属于微分方程的反问题,尤其是将线性多步法的经典数值方法与神经网络相结合,例如多步神经网络。
线性多步法
线性多步法是求解常微分方程数值解的一种常见方法。随着计算机技术的发展,线性多步法得到更加广泛的应用。人们逐渐发现,在某些情况下,线性多步法可以提供更高的数值精度和数值稳定性。此外,线性多步法可以与其他数值方法(如龙格-库塔法)结合使用,互补彼此的优点。
对于上述常微分方程(非自治),设其中结点总数为N,时间间隔h为常数:
$$
h = t_{n + 1} - t_n, n = 1, …, N - 1
$$
则第n个结点的步长为M的线性多步法有以下公式:
$$
\sum_{m=0}^{M}[\alpha_{m}x_{n-m}+h\beta_{m}f(x_{n-m},t)]=0,n=M、\ldots、N, \alpha_{_M}\neq0
$$
使用线性多步法求解常微分方程时,必须选择初始的步长M值,以及确定系数α、β的不同方法,然后可以依次计算n≥M的近似值x_n。
事实上,根据确定系数的方法不同,线性多步法也分为多种类型,本项目中主要使用如下的三种常见的线性多步法:
- Adams-Moulton 法:作为一种隐式方法,需要通过迭代或其他数值求解技术来解决每个时间步长的方程组。它在求解非刚性和刚性常微分方程时都表现良好,并且具有较高的数值稳定性,其精度随步长的减小而提高,但响应地可能会产生更高的计算代价。对于高阶常微分方程,Adams-Moulton 法需要结合相应的差分格式将高阶常微分方程转化为一阶方程组进行求解。
$$
\sum_{m=0}^M\alpha_mx_{n-m}=h\sum_{m=0}^M\beta_mf(x_{n-m})
$$
- Adams-Bashforth法:作为一种显式方法,在求解非刚性和刚性常微分方程时都表现良好,计算效率较高,并且容易实现,但可能会收到稳定性条件地限制,其精度随步长的减小而提高。对于高阶常微分方程,Adams-Bashforth法需要结合相应的差分格式将高阶常微分方程转化为一阶方程组进行求解。
$$
\sum_{m=0}^M\alpha_mx_{n-m}=h\sum_{m=0}^M\beta_mf(x(t_{n-m}))
$$
- 后向微分公式法(Backward Differentiation Formula, BDF):同样是一种隐式方法,但与Adams-Moulton法不同,后向微分公式法是通过解一个非线性方程组来得到当前时间步长的数值解。这个方程组可以用牛顿迭代等数值求解技术来解决。该方法具有较好的数值稳定性,其精度依赖于使用的插值多项式的阶数。一般来说,其高阶形式可以提供更高的精度,但也会增加计算的复杂性。它适用于求解非刚性和刚性常微分方程,并且在稳定性和数值精度方面通常有良好的表现。
$$
\sum_{m=0}^{M}\alpha_{m}x_{n-m}=h\beta f(x(t_{n}))
$$
除此之外,即使采用同一种系数确定方式,选择的步长M不同,得到的系数α、β也有所不同。具体而言,本项目中针对以上三种线性多步法,分别选取步长M=2/3/4的三种情况进行实验测试,下面列出各方法对应不同步长时的系数情况:

线性多步法的优点在于其高阶的精度和较小的计算代价,可以有效地逼近微分方程的数值解。但线性多步法可能会受到稳定性和初始条件的限制,选择适当的步长和求解方法非常重要。
多步神经网络算法
从线性多步法的公式中得到启发,可以用神经网络去反演常微分方程右端的f。通过相等时间间隔h的数值解x的数据训练神经网络,该神经网络的参数可以通过使以下均方误差损失函数MSE最小化来训练得到:
$$
MSE=\frac{1}{N-M+1}\sum_{n=M}^N\parallel y_n\parallel^2
$$
其中:
$$
y_n=\sum_{m=0}^M\left[\alpha_mu_{n-m}+h\beta_mf_{NN}(u_{n-m})\right],n=M,\ldots,N
$$
式中f_NN表示神经网络对函数f的近似,y_n也称为线性多步法(LMM)残差。
在Python中编写函数train()以封装多步神经网络的训练流程:
1 | # 模型训练 |
其中loss_func即为上述定义的均方误差损失函数MSE:
1 | # 损失函数 |
基于多步神经网络改进的常微分方程反演算法
改进的多步神经网络算法
多步神经网络做出了比较理想的假设,即给出了所有的数值解数据是无噪声的,以及神经网络可以表示对常微分方程产生零残差的反演。这种假设是理想化的,我们可以在实际情况下使用改进的方法尝试发现未知常微分方程。
对于多步神经网络,除线性多步法残差之外,如果神经网络能够满足一些通用近似性质,尤其是在多步神经网络反演法效果不佳的非自治常微分方程的反演问题中,可以扩展精确和完整数据的收敛结果。考虑到神经网络对函数近似的强大能力(见通用近似定理),这意味着至少在合适的光滑的常微分方程中存在良好的泛化误差。
假设数据集为给定在若干时刻t_1、t_2、…、t_N的方程的数值解u的值,把每一时刻t_n对应的解u(t_n)记为u^(n),而t_n对应的导数数据一般无从得知。当时间间隔h较小时,可用二阶中心差分法近似求出导数数据,记对于每一时刻t_n求出的导数数据为d^(n),则:
$$
d^{(n)}=\begin{cases}(-3\boldsymbol{u}^{(n)}+4\boldsymbol{u}^{(n+1)}-\boldsymbol{u}^{(n+2)})/2h,\quad n=1,\(\boldsymbol{u}^{(n+1)}-\boldsymbol{u}^{(n-1)})/2h,\quad1<n<N,\(\boldsymbol{u}^{(n-2)}-4\boldsymbol{u}^{(n-1)}+3\boldsymbol{u}^{(n)})/2h,\quad n=N.&\end{cases}
$$
显然二阶中心差分法求导数d^(n)的误差为o(h^2)。
对于常微分方程的反演,我们改进了多步神经网络的损失函数,其中既包含解数据,又包含导数数据:
$$
L=l_1(u,d)+l_2(u,d,f_{NN})
$$
其中:
$$
l_{1}=\frac{1}{N-M+1}\sum_{n=M}^{N}\left|\sum_{m=0}^{M}[\alpha_{m}u_{n-m}+h\beta_{m}f_{NN}(u_{n-m})]\right|^{2}
$$
$$
l_{2}=\frac{1}{N-M+1}\sum_{n=M}^{N}\left|f_{NN}(u_{n})-d_{n}\right|^{2}
$$
$$
n=M,\ldots,N
$$
式中向量范数采用二范数;u为数值解的数据,d为二阶中心差分法得到的导数数据,则有:
- l_1:线性多步法残差,可以表示常微分方程的近似程度
- l_2:均方误差函数,可以表示网络结构的准确度
把u^(n)作为输入,d^(n)作为期望输出进行训练,得到的f_NN即为对函数f的近似。训练流程与改进后的损失函数Python实现如下所示:
1 | # 模型训练 |
可以看到,与改进前相比,在训练过程中增加了对二阶中心差分法得到的导数的相关计算,进一步利用了训练数据中的信息。
1 | # 损失函数 |
值得注意的是,针对非自治常微分方程,由于在将其变换为自治常微分方程时进行了升维操作,这意味着真实的导数向量在y=t这一分量上的值必然是1,因此后续在检验模型训练效果时可利用这一点对模型性能进行先决的把握。
基于误差界理论论证改进算法的优越性
在上述损失函数中,l_1是对目标函数的良好近似,而l_2是神经网络中常用的损失函数。考虑到神经网络对函数近似的强大能力,这意味着即使对于噪声数据,改进的方法也应有良好的泛化能力和鲁棒性。在这里,我们先从理论上来论证改进方法在泛化能力与鲁棒性上的优越性,后续的数值实验部分将采用三类非自治方程的反演来验证改进的多步神经网络的效果。
对于二分类问题(可推广至函数近似的回归问题),当假设空间是有限个函数的集合F={f_1,f_2,…,f_d}时,对任意一个函数f∈F,至少以概率1-δ,以下不等式成立:
$$
R(f)\leq\hat{R}(f)+\varepsilon(d,N,\delta)
$$
其中:
$$
\begin{gathered}R(f)=E[L(Y,f(X))]\\hat{R}(f)=\frac{1}{N}\sum_{1}^{N}L(y_{i},f(x_{i}))\\varepsilon(d,N,\delta)=\sqrt{\frac{1}{2N}(\log d+\log\frac{1}{\delta})}\end{gathered}
$$
式中,R(f)为泛化误差(测试集上的测试风险),\hat{R}(f)为训练集上的经验风险,\hat{R}(f) + ε(d,N,δ)即为泛化误差界。观察上式可知,泛化误差界与样本数N成正比,与假设空间包含的函数数量d成反比。因此,当样本数N越大,泛化误差界越小,当假设空间F包含的函数越多,泛化误差界越大。
根据上述定理,针对改进后的神经网络,有如下不等式成立:
$$
\left|f_{NN}(u^{(n)})-\hat{f}(u^{(n)})\right|\leq\left|f_{NN}(u^{(n)})-d^{(n)}\right|+\left|\hat{f}(u^{(n)})-d^{(n)}\right|\leq w+o(h^{2})
$$
该不等式表明,改进后的损失函数可以拆解成两部分误差:
- 第一部分为通过神经网络得到的导数近似值与通过二阶中心差分法求出的导数之间的误差,设该误差限为w;
- 第二部分为导数真实值与通过二阶中心差分法求出的导数之间的误差,根据二阶中心差分法的基本原理,其误差限为**o(h^2)**。
显然改进后的多步神经网络的泛化误差相较改进前有了进一步的约束,尤其显著减小了噪声对模型的影响,具有更强的泛化能力和鲁棒性。
数值实验与分析
为充分验证改进方法的泛化能力与鲁棒性,我们选取了六个实际的物理问题(对应常微分方程)作为测试用例,对应自治/非自治以及三种不同的线性多步法,在每一个测试用例内选取不同的线性多步法步数以及训练数据所含的高斯噪声方差,对改进前后的两种基于多步神经网络的常微分方程反演方法进行测试。下面我们以“受迫振动方程”这一用例详细展示测试流程,其他的测试用例仅作结果展示。
数值实验流程
数据构建
基于选定的测试用例对应的常微分方程,可采用如下步骤生成原始的真实数据集:
- 在所给区域内均匀选取间隔为h的N个结点t_n,n=1,2,…,N ,使用Python中的Scipy库求出各结点对应的数值解u^(n);
- 将数值解u^(n) 代入二阶中心差分法中得到每个x_n 对应的导数值d^(n) ;
- 噪声数据构建:在各结点对应的数值解u^(n) 上依次加上期望为0,方差为0、0.01、0.05的高斯噪声。
在Python中,用函数get_data()函数实现了数据构建的代码封装:
1 | def get_data(t0, t_end, h, y0, noise_std=0.0): |
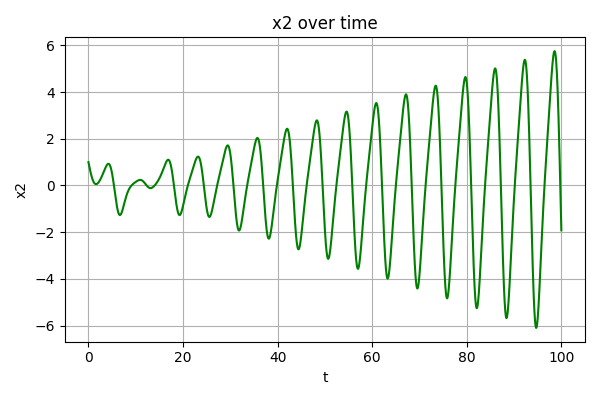
以“受迫振动方程”这一测试框架为例,force_oscillator函数中刻画了该场景下的微分方程规律:
1 | def forced_oscillator(t, y): |
生成的无噪声数据如下图所示:

神经网络训练
根据上述算法理论部分列出的训练流程框架,适用数据(u,d)对神经网络进行训练,训练后得到的函数f_NN即为对函数f的近似。
关于神经网络的结构与参数,本项目中所使用的神经网络结构均相同(后续不再赘述),均包含4个隐藏层,每层128个神经元,激活函数为tanh,Python中基于pytorch框架对神经网络架构的实现如下:
1 | import torch.nn as nn |
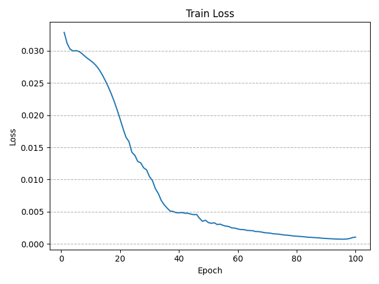
训练过程中实时记录了每一个epoch的损失函数值,下图分别绘制了改进前后的多步神经网络在无噪声数据集上训练过程中损失函数值的变化情况(总Epoch=100),可以看到损失函数均呈收敛态势,且改进后的多步神经网络收敛更快:

效果检验
为定量地比较改进前后的多步神经网络的泛化性能与鲁棒性,采取如下的实验步骤进行训练后模型的效果检验:
- 用训练得到的函数f_NN解方程得到数值解u_NN^(n) ,观察近似效果,计算均方误差mse_x 和平均绝对误差mae_x并与多步神经网络作比较;
- 用数值解u^(n)代入训练得到的函数f_NN得到的导数的近似值d_NN^(n),将u^(n)代入给定的常微分方程中的 f 得到导数的真实值d^(n),计算均方误差mse_f和平均绝对误差mae_f并与多步神经网络作比较。
其中用于比较性能的指标均方误差mse和平均绝对误差mae的定义式如下所示:
$$
mse_{x}=\frac{1}{ND}\sum_{n=1}^{N}\left|u_{NN}^{(n)}-u^{(n)}\right|_{2}^{2}
$$
$$
mse_{f}=\frac{1}{ND}\sum_{n=1}^{N}\left|d_{NN}^{(n)}-d^{(n)}\right|_{2}^{2}
$$
$$
mae_{x}=\frac{1}{ND}\sum_{n=1}^{N}\left|u_{NN}^{(n)}-u^{(n)}\right|_{1}
$$
$$
mae_{f}=\frac{1}{ND}\sum_{n=1}^{N}\left|d_{NN}^{(n)}-d^{(n)}\right|_{1}
$$
Python中将利用训练好的模型进行预测的过程封装成函数predict_u,指标计算直接调用scikit-learn函数库中的相关函数:
1 | def rhs(t, u_np): |
在“受迫振动方程”这一测试案例中,基于训练轮数Epoch=50的模型,运行以上检验流程,得到如下检验指标数据:
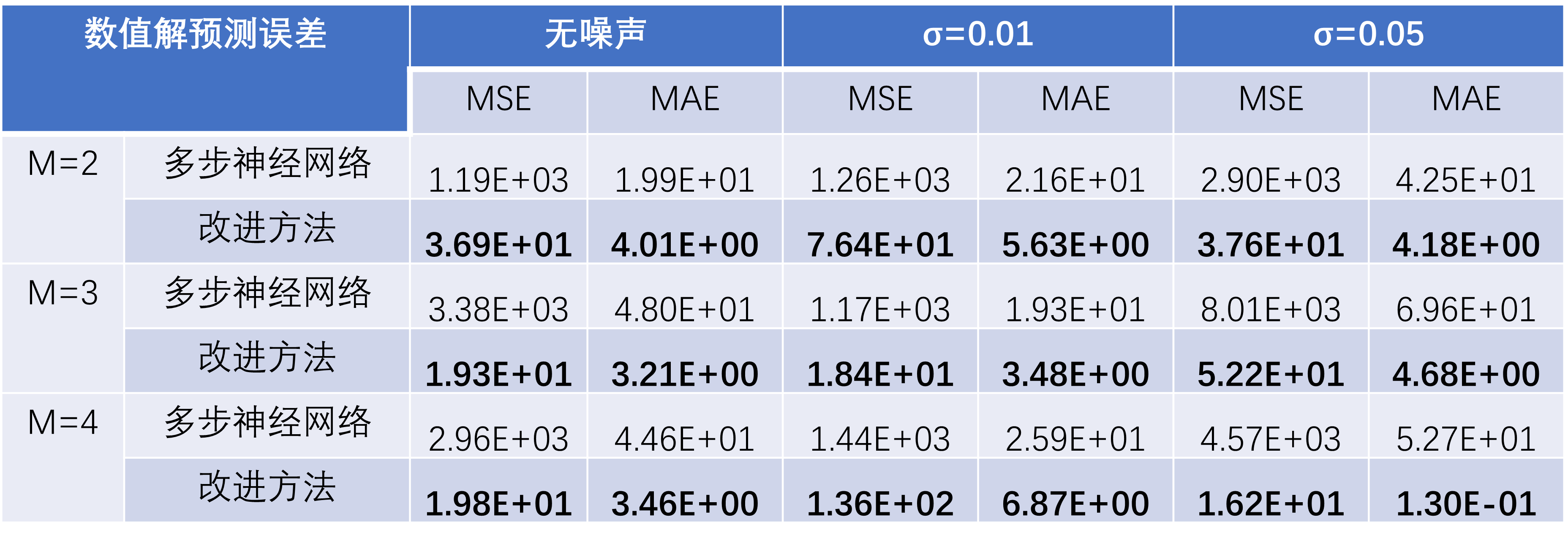
可以看到,随着噪声强度增加,两种方法的误差均增大,但改进方法对数值解的预测误差在各种情况下均小于多步神经网络。
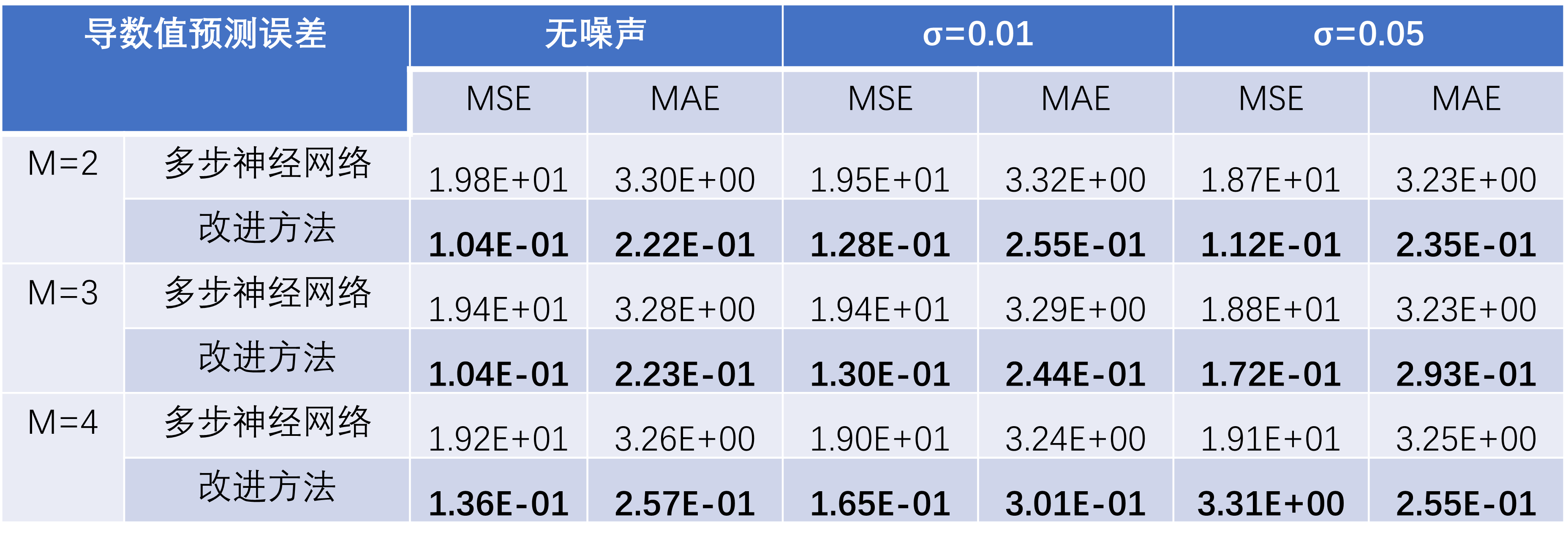
可以看到,当数据无噪声时,本文提出的改进方法对于受迫振动方程的近似效果强于多步神经网络;随着噪声强度的增加,多步神经网络的误差大幅增加,而改进的方法的误差一直保持较小且始终强于多步神经网络。
除此之外,针对在无噪声数据集上训练轮数分别为Epoch=100和Epoch=500时的模型,将其作为微分方程中的f用于预测数据的生成,效果分别如下图所示:
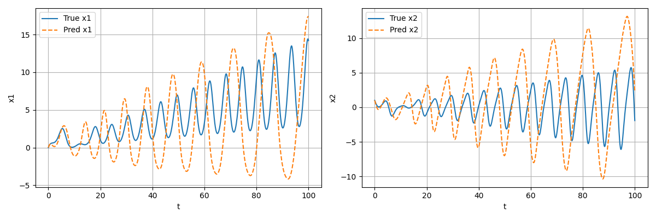
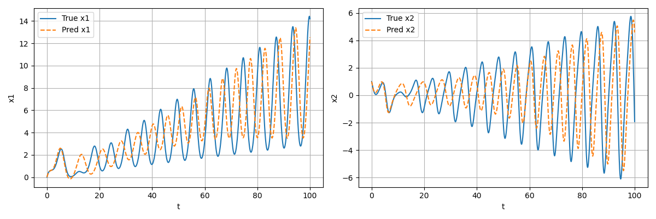
可以看到,随着训练轮数的增加,模型对于实际微分方程的拟合效果越来越好,生成的预测数据也越来越接近用于训练的真实数据;事实上,从理论上讲,大概在训练轮数Epoch达到10^4数量级时才会有较为精准的拟合效果,本项目由于用于训练的计算资源有限,仅进行了最大训练轮数为1000的测试。在后续的结果分析部分,将直接采用高训练轮数下的精确结果进行展示。
数值实验结果分析
非自治常微分方程
受迫振动方程——Adams-Moulton法
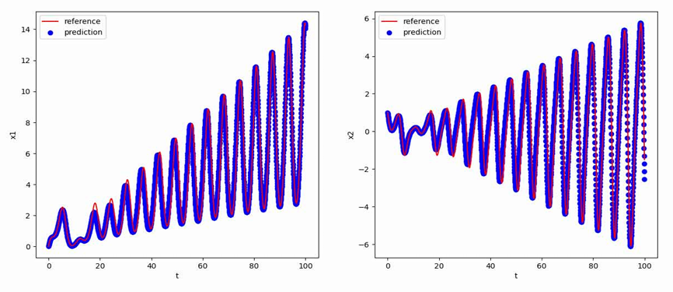
受迫振动方程(Forced Oscillator)是描述一个振动系统在外界力的作用下进行振动的方程。这个方程可以用来研究各种物理系统中的振动现象,例如弹簧振子、摆锤、电路振荡等。受迫振动方程的核心思想是将外界力引入方程中,以描述振动系统在外界激励下的行为。受迫振动方程的研究对于科学、工程和技术领域具有重要意义。它不仅有助于我们深入理解振动现象的本质和规律,还为我们设计和优化振动控制系统、减振装置等提供了理论基础。同时,它在电子设备、结构工程、交通运输等方面也有广泛的应用。
实验使用的受迫振动方程如下:
$$
\begin{aligned}&\frac{dx_1}{dt}=x_2,\&\frac{dx_2}{dt}=-cosy\cdot x_1-x_2+\frac{y}{50},\&\frac{dy}{dt}=1\end{aligned}
$$
使用[0,1,0]T作为初值,生成从t=0到t=100,间隔h=0.05的数据作为训练集,最终得到的多步神经网络对常微分方程的反演效果如下图所示,其中红色曲线是原方程数值解的曲线,蓝色点是用无噪声数据训练的函数f_NN代替f得到的数值解:
线性标量方程——Adams-Bashforth法
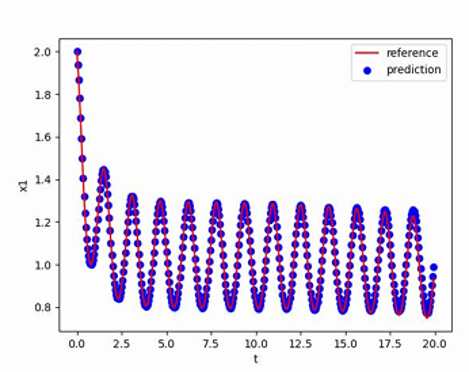
线性标量方程(Linear Scalar Equation)是一种描述某个未知函数与其导数之间的关系的方程,其中未知函数的导数的最高次数为1。线性标量方程是微分方程中的一类重要问题,它在数学物理等领域中有广泛应用。线性标量方程的研究对于数学、物理学和工程学等领域具有重要意义。它可以用来描述动力学系统的行为、传热和传质过程、量子力学中的波函数演化等。通过分析和求解线性标量方程,可以深入理解系统的特征、稳定性、渐近行为等,为问题的模拟、控制和优化提供理论基础。在现代科学和工程中,线性标量方程的研究得到了进一步推广和延伸。例如,非线性标量方程、偏微分方程等是线性标量方程的扩展和推广,它们更好地描述了一些复杂的物理现象和现实问题。
实验使用的线性标量方程如下:
$$
\frac{dx_1}{dt}=-x_1(sin4y+1)+cos\frac{y^2}{1000},
$$
$$
\frac{dy}{dt}=1
$$
使用[2,0]T作为初值,生成从t=0到t=20,间隔h=0.05的数据作为训练集,最终得到的多步神经网络对常微分方程的反演效果如下图所示,其中红色曲线是原方程数值解的曲线,蓝色点是用无噪声数据训练的函数f_NN代替f得到的数值解:
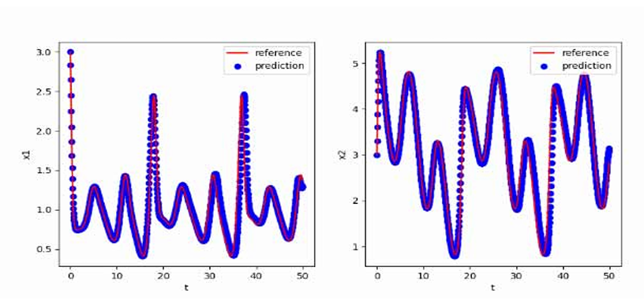
食饵-捕食者模型方程——后向微分公式法
食饵-捕食者模型(Predator-prey Model)是生态学中研究食物链和生物群落动力学的重要模型之一,描述了食物链中食饵(被捕食者)和捕食者之间的相互作用关系。这种模型的研究对于我们理解生态系统的稳定性、物种相互作用以及生态系统中物种数量的变化具有重要意义。通过食饵-捕食者模型,我们可以研究食饵与捕食者之间的数量关系以及它们之间的相互作用。一般来说,食饵的数量被认为是捕食者的食物来源,并且捕食者的数量受到食饵的供给和捕食行为的影响。该模型通常描述了食饵数量随时间的变化,以及捕食者数量随时间的变化。食饵-捕食者模型的研究对于生态学、环境保护和资源管理等领域具有重要意义。通过该模型,我们可以深入了解生态系统中物种数量的变化规律,从而预测物种灭绝和生态系统崩溃的风险,以及寻找保护和管理生物多样性的方法。
实验使用的食饵-捕食者模型方程如下:
$$
\begin{aligned}&\frac{dx_1}{dt}=x_1-x_1\cdot x_2+sin\frac{y}{2}+cosy+2,\&\frac{dx_2}{dt}=x_1\cdot x_2-x_2,\&\frac{dy}{dt}=1\end{aligned}
$$
使用[3,3,0]T作为初值,生成从t=0到t=50,间隔h=0.05的数据作为训练集,最终得到的多步神经网络对常微分方程的反演效果如下图所示,其中红色曲线是原方程数值解的曲线,蓝色点是用无噪声数据训练的函数f_NN代替f得到的数值解:
自治常微分方程
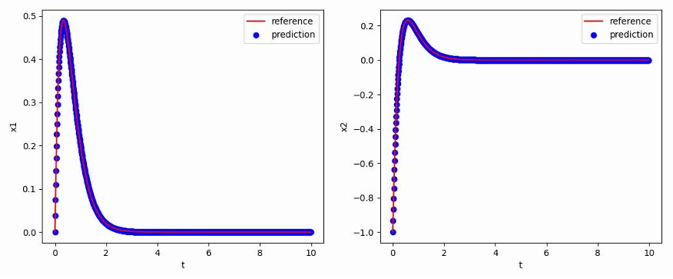
线性常微分方程——Adams-Moulton法
线性常微分方程(Linear ODEs)是微分方程中的一类重要问题,它描述了未知函数及其导数之间的线性关系。线性常微分方程的研究对于数学、物理学和工程学等领域具有重要意义。它们出现在物理学中许多基础问题的数学描述中,例如弹簧振动、电路分析、传热过程等。在工程学中,线性常微分方程也广泛应用于控制系统的建模和分析。随着科学技术的发展,研究者提出了各种各样的数值方法和近似方法,以求解复杂的线性常微分方程。这些方法包括欧拉方法、龙格-库塔方法、有限差分方法、变分法等,它们为实际问题的求解提供了有效的数值工具。随着对非线性动力学系统的研究和认识的深入,研究者们开始将非线性常微分方程引入到线性常微分方程中,以描述更为复杂的现象和现实问题。
实验使用的线性常微分方程如下:
$$
\frac{dx_1}{dt}=x_1-4x_2,
$$
$$
\frac{dx_2}{dt}=4x_1-7x_2
$$
使用[0,-1]T作为初值,生成从t=0到t=10,间隔h=0.01的数据作为训练集,最终得到的多步神经网络对常微分方程的反演效果如下图所示,其中红色曲线是原方程数值解的曲线,蓝色点是用无噪声数据训练的函数f_NN代替f得到的数值解:
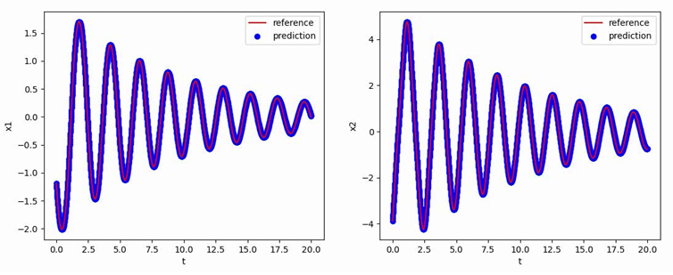
阻尼三次振子方程——Adams-Bashforth法
阻尼三次振子(Damped Cubic Oscillator)是一种物理系统,它描述了受到阻尼力和弹力作用的振动系统。阻尼指的是系统中存在能量损耗的因素,如摩擦力,它会导致振动的逐渐减弱;三次振子表示系统的势能函数是一个三次函数,它具有非线性的特性。阻尼三次振子最早出现在振动力学和非线性动力学的研究中。对于振动系统的研究是物理学、工程学和应用数学等领域的重要课题之一。阻尼三次振子的研究对于理解和预测复杂动力学系统的行为具有重要意义。通过分析阻尼三次振子的运动规律和稳定性,我们可以深入了解非线性振动系统的动力学特性,例如振动的周期性、混沌行为等。这些研究也为控制系统、电子电路、力学系统等领域的工程应用提供了参考和启示。
实验使用的阻尼三次振子方程如下:
$$
\frac{dx_1}{dt}=-0.1x_1^3+2x_2^3,
$$
$$
\frac{dx_2}{dt}=-2x_1^3-0.1x_2^3
$$
使用[1,1]T作为初值,生成从t=0到t=25,间隔h=0.01的数据作为训练集,最终得到的多步神经网络对常微分方程的反演效果如下图所示,其中红色曲线是原方程数值解的曲线,蓝色点是用无噪声数据训练的函数f_NN代替f得到的数值解:
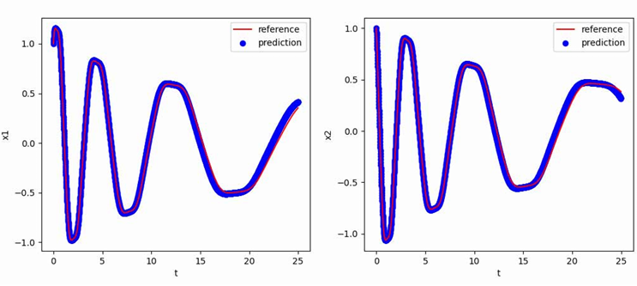
阻尼简谐摆方程——后向微分公式法
阻尼简谐摆(Damped Pendulum)是一个经典力学中的物理系统,它由一个具有质量的物体通过一根轻质绳或杆与一个固定支点相连接组成。阻尼简谐摆在受到重力作用下,沿着一条弧线进行周期性振动。阻尼简谐摆的研究对于理解和预测振动系统的行为具有重要意义。通过分析阻尼简谐摆的运动规律和稳定性,我们可以深入了解振动系统在存在阻尼时的响应特性,例如振动的振幅、频率等。这些研究不仅在理论物理学中具有重要意义,也为工程学中的控制系统、机械振动和结构动力学等领域的应用提供了基础。
实验使用的阻尼简谐摆方程如下:
$$
\begin{aligned}&\frac{dx_1}{dt}=x_2,\&\frac{dx_2}{dt}=-\alpha x_2-\beta\sin x_1,\&\alpha=0.2,\beta=8.91\end{aligned}
$$
使用[-1.193,-3.876]T作为初值,生成从t=0到t=20,间隔h=0.01的数据作为训练集,最终得到的多步神经网络对常微分方程的反演效果如下图所示,其中红色曲线是原方程数值解的曲线,蓝色点是用无噪声数据训练的函数f_NN代替f得到的数值解:
研究结论与创新
研究结论
本项目针对常微分方程的反演问题提出了一种基于多步神经网络改进的常微分方程反演算法,旨在从数据中提取内含的常微分方程。通过将导数数据融入训练数据,我们改进了多步神经网络的数据集,并优化了神经网络的损失函数,以提高模型的准确性和泛化能力。经过训练,改进的神经网络成功拟合原方程中的函数,实现了对非自治常微分方程的反演。我们还推导并讨论了改进算法的误差界。我们进一步将改进的算法应用于自治常微分方程反演,通过训练网络拟合原方程函数,拓展了算法在自治常微分方程反演中的适用性。
本项目通过实验以非自治常微分方程中的受迫振动方程、线性标量方程和食饵-捕食者模型方程,以及自治常微分方程中的线性常微分方程、阻尼三次振子方程和阻尼简谐摆方程为例,展示了算法的有效性。在实验中,我们添加了不同强度的噪声,并利用改进算法对常微分方程进行反演。实验结果表明,改进方法在大多数情况下优于多步神经网络,在处理有噪声数据时表现更为出色。这些结果充分验证了本文提出的方法在反演问题中的可行性和优越性。
研究方法创新性
传统方法通常利用多步神经网络来处理常微分方程的反演问题,主要集中在处理自治常微分方程,对于非自治常微分方程的反演效果不尽理想,特别是在使用带有噪声数据进行训练时表现不佳。本研究首次将研究重点聚焦于非自治常微分方程的反演,通过将非自治方程转化为自治方程的形式,提出了一种新的研究思路。针对带有噪声数据的方程反演问题,采用了改进损失函数的方法以提升算法的鲁棒性。此外,将这种新方法扩展应用于自治常微分方程的反演问题,结果显示其反演效果明显优于多步神经网络。这一新思路对解决常微分方程反演问题带来了一种新的方法。
参考文献
[1] 王开荣,杨大地编著.应用数值分析[M].高等教育出版社,2010.
[2] 付长铠.常微分方程反演的机器学习方法研究[D].长春工业大学,2024.
[3] Raissi M, Perdikaris P, Karniadakis G E. Multistep neural networks for data-driven discovery of nonlinear dynamical systems[J]. arXiv preprint arXiv:1801.01236, 2018.
[4] 李航. 统计学习方法[M]. 第二版. 北京:清华大学出版社, 2019.
[5] 陈新海, 刘杰, 万仟, 等. 一种改进的基于深度神经网络的偏微分方程求解方法[J]. 计算机工程与科学, 2022, 44(11): 1932-1940.