3D-VLA:A 3DVision-Language-Action Generative World Model
Date:2024-3-14
论文链接:https://arxiv.org/abs/2403.09631
原文代码仓库:[UMass-Embodied-AGI/3D-VLA: [ICML 2024] 3D-VLA: A 3D Vision-Language-Action Generative World Model]
提出了 3D-VLA,通过生成世界模型无缝地将 3D 感知、推理和行动联系起来。具体来说,3D-VLA 构建在基于 3D 的大型语言模型(3D-LLM)之上,并引入了一组交互tokens来与具体环境互动。此外,为了将生成能力注入模型,还训练了一系列扩散模型,并将它们对齐到LLM用于预测目标图像和点云的模型中。3D-VLA 显着提高了具身环境中的推理、多模态生成和规划能力,展示了其在实际应用中的潜力。
Background
- 已有模型存在的问题:
- RT-2、PALM-E等VLA模型已经可以根据2D图像生成高级计划或低级行动,但人类位于一个比2D图像更丰富的3D物理世界中,需要根据对环境的3D理解进行推理、计划和行动,而目前的VLA模型依赖于2D输入,缺乏与更广泛的3D物理世界领域的集成。
- 目前已有的3D具身模型可以在3D环境中进行规划与行动,但此类模型仅通过学习从感知到行动的直接映射来执行动作预测,而忽略了世界的巨大动态以及动作与动态之间的关系。相比之下,人类被赋予了世界模型,这些模型描绘了对未来场景的想象,以相应地规划行动。
- 构建类似人类的3D世界模型带来的挑战:
- 已有的模型局限于语言这一单一模态
- 现有的具身数据集主要包含 2D 图像或视频,缺乏用于 3D 空间推理和规划的 3D 相关注释
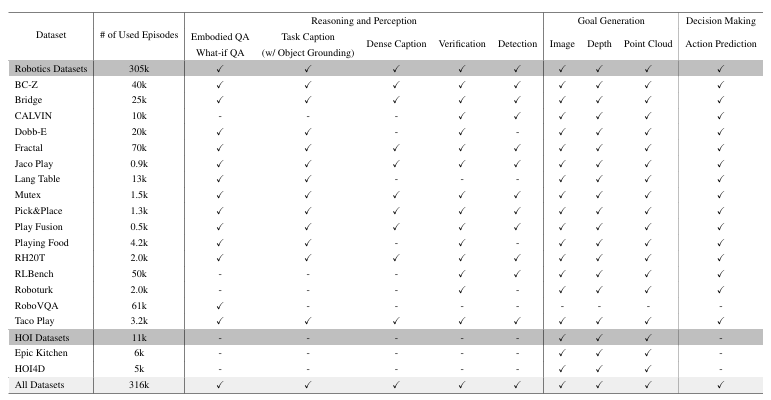
Dataset:3D embodied instruction tuning datasets

出发点:已有的数据集(视频-动作对)大多不提供深度或 3D 注释以及机器人操作中的精确控制,而如果没有 3D 信息,机器人很难理解和执行需要 3D 空间推理的命令(“将最远的杯子放入中间抽屉”)
构建方式:从已有的具身数据集(12个数据集:语言指令/图像/深度信息/模拟环境/人机交互/3D注释)中提取3D-语言-动作对,得到如下信息的标注:点云、深度图、3D bounding boxes;机器人7D动作(与RT系列文章一致,x/y/z/roll/pitch/yaw/抓持器打开);文本描述
视觉标注
- 获取3D点云数据:基于深度图数据,可使用相机标定内参/姿态数据将RGB-D图像升维至3D点云
- 估计深度:ZoeDepth
- 估计光流:RAFT
光流(optical flows):提炼生成数据——在摄像机姿态不变的视频片段中,用于估计哪些像素背景未移动,并将这些背景的深度图对齐到同一视频的不同帧中,同时将每帧的深度图乘以一个系数,以确保深度一致性。
生成3D标注:
- 对象的 3D 边界框(bounding box):
- 使用spaCy解析获取指令(数据集提供文本指令以描述机器人执行的命令)中的所有名词块(包括操作对象)
- 采用预训练的映射/对齐模型(grounding model)(如Grounded-SAM)获取各对象的2D蒙版,并根据有效光流区域中的最高置信度值来选择操作对象
- 通过将2D蒙版升维至3D点云中,获取空间中所有对象的3D bounding box
由于重建了深度和点云,因此可以在未来的帧中使用图像、深度和点云作为ground truth。
- 3D 空间中的机器人动作:数据集中已提供7D机器人动作
- 对象的 3D 边界框(bounding box):
语言标注
生成密集的语言标注,其中包含围绕在生成的3D视觉标注周围的tokens:采用带有tokens的预训练语言模板,将3D标注构建至提示词与答案中
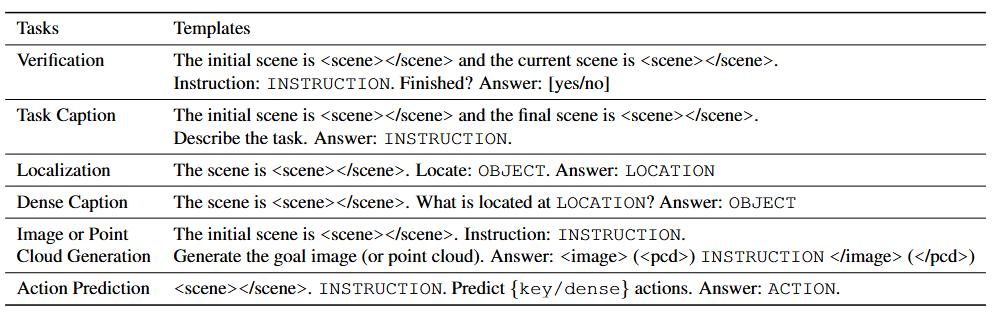
e.g. I should
pick up
the chip bag [loc tokens] </img /pcd>
使用基于ChatGPT的提示词工具,使提示词prompt更加多样化:
- 向 ChatGPT 提供指令和标注对象及其bounding box,要求 ChatGPT 总结信息并将模板生成的提示重写为更多样化的形式;
- 提供 2-3 个人工编写的小样本演示,以指导 GPT 了解它被指示生成的数据类型;
- 对于没有预定义模板的任务,ChatGPT 也会被要求自行生成提示和答案作为这些任务的语言输入和输出。

Model
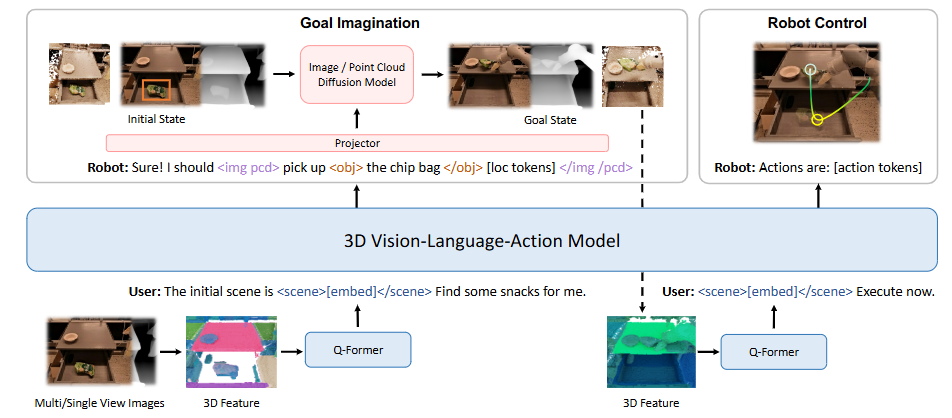
3D-VLA是一个用于具身环境中的三维推理、目标生成和决策的世界模型。
以3D-LLM作为backbone,在此之上构建主干开发 3D-VLA 基础模型
- 由于收集的数据集无法达到多模态LLM从头开始训练所需的十亿级规模,因此需要利用多视图特征生成 3D 场景特征。这使得视觉特征能够无缝集成到预先训练的 VLM 中,无需调整。
- 3D-LLM的训练数据集主要包括对象和室内场景,这与该模型所用数据集的具体设置并不直接一致,因此选择不加载 3D-LLM 预训练模型,而是使用 BLIP2-FlanT5_XL作为预训练模型。
- 训练期间解冻了 token 的输入和输出嵌入,以及 Q-Former 的权重。
添加一系列交互(interaction)tokens:进一步增强模型对 3D 场景的理解以及与3D世界交互的能力
- 在句中的物体名词两侧加入token:
,使得模型可以更好地捕获需要操作/提到的对象
e.g.,
a chocolate bar [loc tokens] on the table- 为了更好地通过语言表示空间信息,设计了一组位置tokens:
,用于定位提到的对象,这些标记由 AABB 形式的 3D bounding box 的六个tokens表示 - 为了更好地使用框架对动态进行编码,引入了tokens:
- 通过一组扩展的代表机器人动作的专用tokens进一步增强架构:机器人的动作具有 7 个自由度,由离散tokens(如
, ,<gripper0/1> )表示,他们代表了机器人手臂的预期绝对位置(x/y/z)、旋转角度(roll/pitch/yaw)、抓手打开度。这些动作由token : 分隔。
- 在句中的物体名词两侧加入token:
将目标生成(图像-深度/点云)能力注入3D-VLA
人类**预先可视化场景的最终状态**,以便于行动预测或决策,这是构建世界模型的一个关键方面。此外,通过初步实验可以发现,提供基本事实的最终状态可以增强模型的推理和规划能力。
训练多模态大语言模型来生成图像、深度和点云主要存在以下问题,文章中根据这两点给出了对应的模型设计优化方案:
视频扩散模型并不是为具体的某种模态量身定制的——根据不同的模态(如图像、深度和点云)对具体的扩散模型进行预训练
利用选取的3D-语言视频数据来训练条件扩散模型,该模型根据指令编辑初始状态模态,以生成相应的最终状态模态。
- RGB-D to RGB-D:采用Stable Diffusion V1.4作为预训练模型,将RGB潜变量和深度潜变量连接起来作为图像条件。
- 点云 to 点云:采用Point-E作为预训练模型,添加点云的条件输入。
如何将各种模态的扩散模型纳入一个单一基础模型——使用投影器将这些扩散模型的解码器与3D-VLA 基础模型的嵌入空间对齐
在对扩散模型进行预训练后,配备各种解码器,这些解码器可以在其模态中调节潜空间来生成目标:图像
和点云
在图像/点云的tokens封装之间,监督LLM生成的给机器人操作的指令,包括目标和位置tokens。
e.g.
pick up the
apple [loc tokens]基于此,可以使用基于transformer的投影器,将解码器的特征和嵌入(embedding)从LLM映射到扩散模型的空间中,从而建立高级语言支持和多模态目标生成之间的联系,增强模型理解并提高生成多模态数据的能力。
为了提高训练3D-VLA的效率并避免灾难性遗忘,利用LoRA来微调不同的扩散模型。
只训练新引入的特殊tokens embedding、相应的embedding输出线性层和整个投影器,训练目标是同时最小化LLM和扩散模型的去噪损失。
Experiment:模型评估
3D推理与定位
测试任务(基于Open-X数据集):
- Embodied QA
- Task Caption(输入初始和最终场景,要求推理这个过程中发生了什么)
- What-if QA(与RT-1相同,指令拆解)
- Dense Caption(3D场景的过程推断)
- 定位:以zero-shot方式检测 2D 边界框,然后使用深度投影将它们传输到 3D 边界框
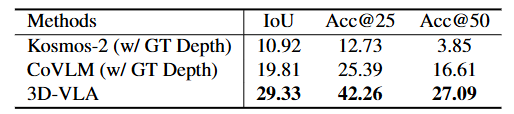
对比Baseline模型:3D-LLM、2D-VLM(BLIP2、OpenFlamingo、LLaVA)、2D 对齐 MLLM(Kosmos-2、CoVLM)【针对任务5定位】
测试方式:
- zero-shot(在未见的数据集上测试)
- 在训练集(2D 图像-指令-行为对)上测试
测试结果:
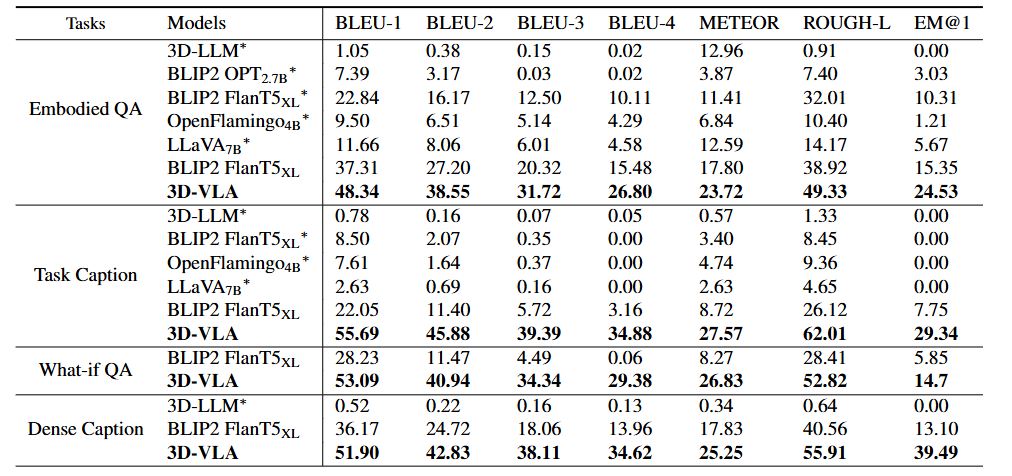
- 3D-VLA 在语言推理任务上优于所有 2D VLM 方法
- 3D-LLM 在机器人推理任务上表现不佳
- 3D-VLA 在定位性能方面表现出优于 2D 基线方法的明显优势
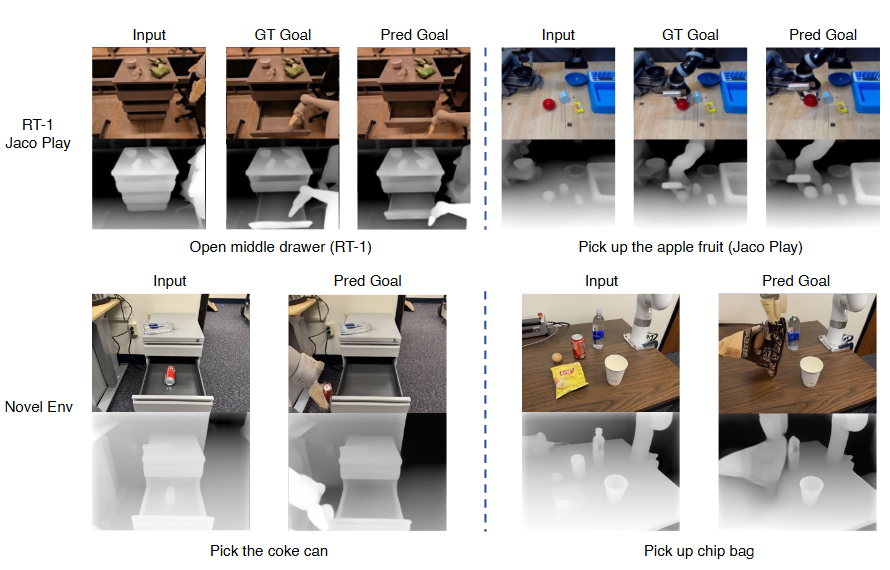
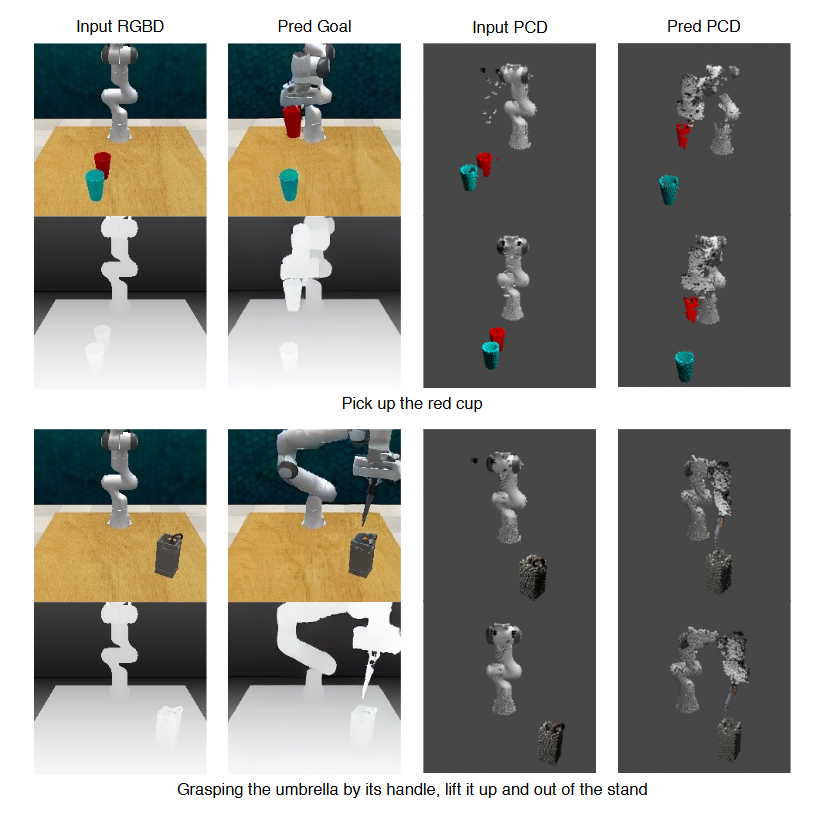
多模态目标生成
测试任务:从 Open-X 测试集中随机抽样了 4000 个未见的episodes,定量评估Open-X 测试集上 3D-VLA 的 RGB 目标和点云目标生成能力
对比Baseline模型:
- 图像生成:图像编辑方法 Instruct-P2P、目标图像/视频生成方法SuSIE、具有图像生成能力的大语言模型 NeXT-GPT
- 点云生成:文本-to-3D 扩散模型Point-E
测试结果:
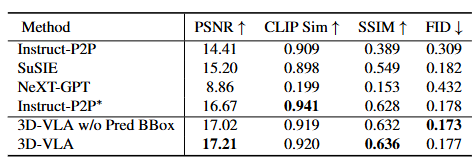
- 图像目标生成:
- 与直接zero-shot到机器人领域的现有生成方法(表中的第 1、2、3 行)相比,3D-VLA 在大多数指标方面都取得了有希望的性能
- 即使与采用相同机器人数据集(表中第 4 行)上训练的 Instruct-P2P* 直接比较,3D-VLA 的性能也始终优于它
- 从输入提示(第 5 行)中排除预测的边界框时,性能略有下降
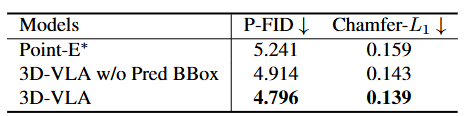
点云生成:
- 具有中间预测边界框的 3D-VLA 性能最佳
- 图像目标生成:
机器人行动规划
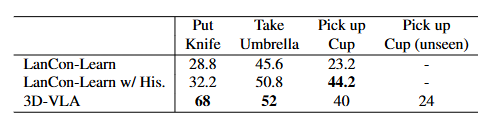
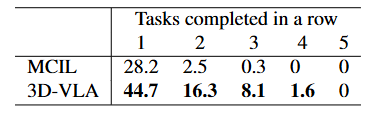
测试任务:根据RLBench和CALVIN两个benchmark dataset评估3D-VLA 预测机械臂动作的能力
- RLBench:选择3个任务进行评估;从pick-up-cup任务中选择var1作为未见任务以测试模型泛化能力
- CALVIN:在long-horizon multi-task language control设置下按顺序执行5个任务;在场景A、B、C、D中训练并在场景D中测试
对比Baseline模型:
- RLBench:LanCon-Learn(一种多任务方法,可根据指令条件输出预测动作)
- CALVIN:MCIL(一种序列-to-序列的条件变分自动编码器)
测试结果:
- 3D-VLA在大多数任务中和RLBench的行为预测baseline性能相当甚至更优,说明其行为规划能力优越
- pick-up-cup任务很好地证明了模型的泛化能力
- 3D-VLA 在 CALVIN 中也取得了良好结果