RT-1:Robotics Transformer for Real-world Control at Scale
Date:2022-12-14
论文链接:https://arxiv.org/abs/2212.06817
原文代码仓库:google-research/robotics_transformer
模型使用数据集:gresearch – 存储桶详情 – Cloud Storage – Google Cloud Console
提出具有高容量结构(with high-capacity architectures)的Vision-Language-Action(VLA)多模态大模型Robotics Transformer,结合真实机器人执行实际任务时所收集到的大规模数据(all of the diverse, robotic data:图像/视觉-语音/语言-行为),进行开放式的任务无偏训练(open-ended task-agnostic training),从而提高模型的可扩展性,但模型充分利用大规模数据集的能力仍然有限。
Background
- 在计算机视觉(CV)、自然语言处理(NLP)或语音识别等下游任务中,通过在多样化且任务无偏的大型数据集上进行预训练,现代机器学习模型已经可以在零样本(Zero-Shot)学习与在特定任务的小数据集上进行微调(迁移学习)中有良好的表现;
- 这种技术在机器人中仍未得到广泛运用,同时由于真实世界中的机器人数据难以收集,需要对其可行性进行验证,重点需要关注模型的泛化与微调能力。
Model
工作平台:移动机械手 from Everyday Robots——7自由度手臂+两指夹持器+移动基座
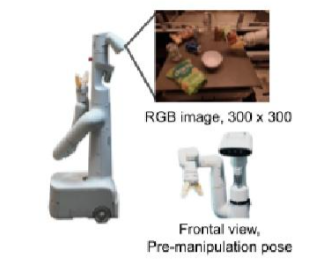
工作模式:接收图像短序列和自然语言指令->输出离散化的基底和手臂动作供机器人在每个时间步执行(闭环控制),直到产生终止动作或用完预设时间步数
动作包括手臂运动的七个维度(x、y、z、roll、pitch、yaw、抓持器打开)、底座运动的三个维度(x、y、yaw)和一个额外的离散维度,用于在三种模式之间切换:控制手臂、控制基座或终止。
参数规模:35M
处理频率:3Hz——100ms推理时间 + 280ms执行延迟
基本架构:
基于Transformer——将高维输入和输出(包括相机图像、文本指令和电机命令)编码成紧凑的token表示供Transformer使用,以高效推理与实时控制
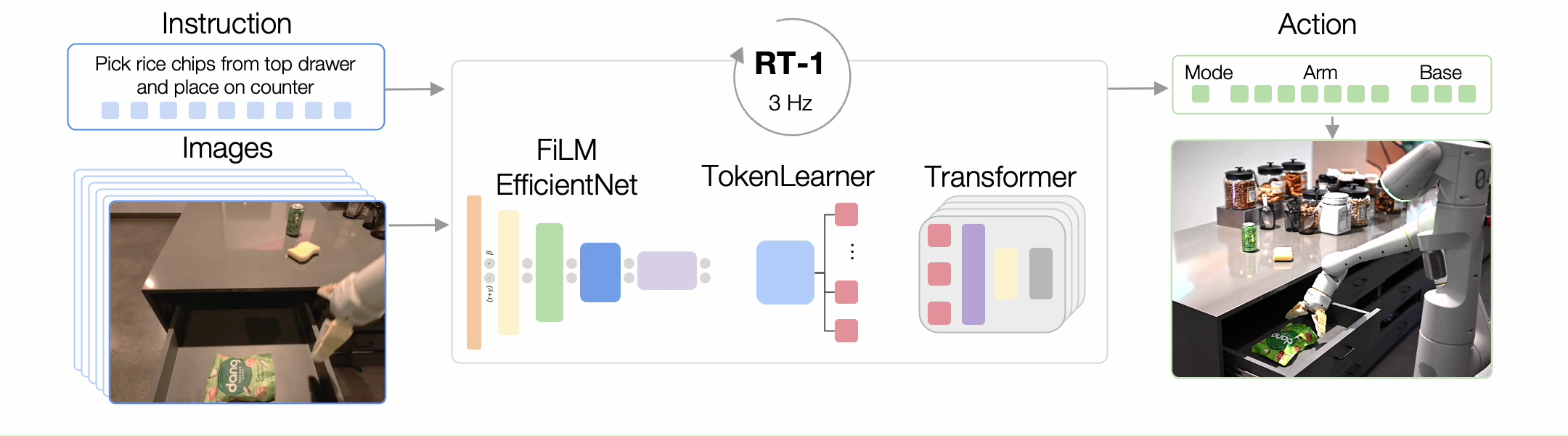
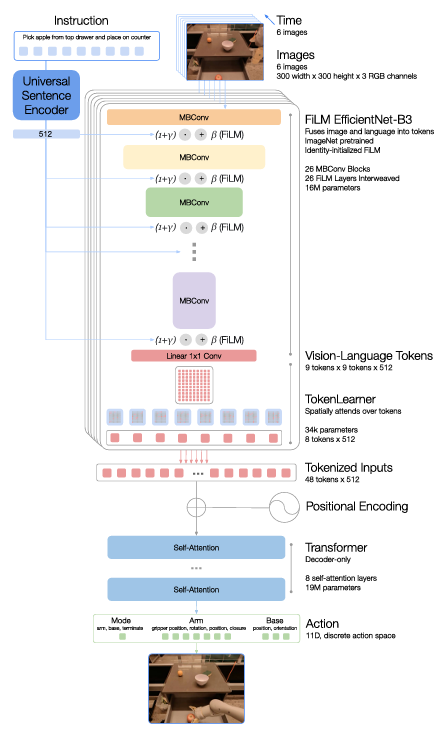
图像和指令(文本)的处理(tokenization):
- 总体上采用基于 ImageNet 数据集预训练的卷积神经网络 EfficientNet-B3 作为基本框架,在此基础上嵌入预训练的语言编码器进行条件化,以提取与任务指令相关的图像特征
- 参数规模:16M
- 架构:26层【MBConv模块+FiLM层】
- 文本:文本输入Universal Sentence Encoder->嵌入EfficientNet中添加的FiLM层(将产生FiLM仿射变换的密集层(fc和hC)的权重初始化为零,允许FiLM层最初作为恒等映射并保留预训练权重的功能,防止破坏中间激活)
- 图像:输入6张300 * 300的3通道图像->经由CNN输入9 * 9 * 512空间特征图(每张图像)->展平为81个视觉标记
Token Learner 模块:
- 为加速推理,设计该元素注意力模块用于压缩所需注意的tokens数量(81->8)
- 允许基于指令信息软选择图像tokens,只传递重要的token组合给后续的Transformer层
- 参数规模:34k
Transformer :
- 仅有解码器的序列模型
- 参数规模:19M
- 架构:8个自注意力层
- 输入:每张图像8tokens * 6张输入图像->48个总tokens(添加位置编码)
- 输出:动作tokens(7-dim arm movement + 3-dim base movement + 1-dim 状态切换,共11个维度;对于每个维度,在其变量范围内均匀离散化为256个bin)
损失函数:标准分类交叉熵熵目标与因果掩码
Data
数据规模:用时17个月,通过13个机器人采集了130k+ episodes ,包含700+指令
工作场景:办公室厨房场景(2个真实办公室厨房场景Kitchen1、Kitchen2+1个根据真实场景Kitchen1建模的训练环境)


技能:包括挑选、放置、打开和关闭抽屉、将物品放入和取出抽屉、将细长的物品直立放置、将直立放置的细长物品撞倒、拉餐巾纸和打开罐子
指令:包含一个动词和一个或多个描述目标对象的名词;为组合这些指令,将它们分割成一些技能(如动词“pick”、“open”或“place upright”)和对象Object(如名词“可乐罐”、“苹果”或“抽屉”);添加新指令时不对特定技能做出任何假设以提高其扩展性。


Experiments
对比的Baseline:Gato和BC-Z(基于相同的训练数据集)
Gato:只计算单张图像标记,无语言嵌入,且无推理时间优化(TokenLearner与删除自动回归动作);为保证实时性,将模型参数规模限制在37M
BC-Z:作为前馈模型不使用先前时间步,且使用连续动作标记;原模型参数量小于RT-1, 因此额外对比了一个参数规模和RT-1类似的BC-Z模型BC-ZXL
主要关注如下问题:
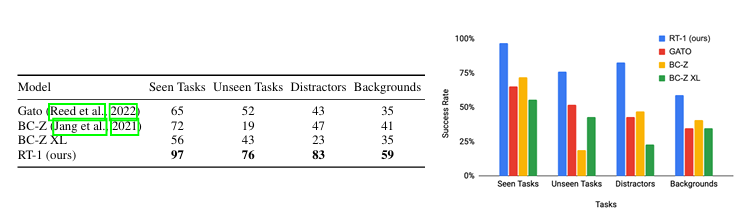
已见任务的执行性能:
从训练集中随机抽样出部分指令进行测试(仅指令已见,物品位置、时间、机器人初始位置等因素随机):测试任务200+(36个抓取物体的任务,35个推倒物体的任务,35个将物体竖直放置的任务,48个移动物体的任务,18个打开和关闭不同抽屉的任务,以及36个从抽屉中取出和放入物体的任务)
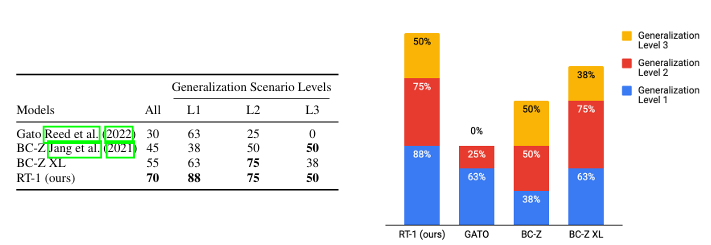
未知任务的泛化性能:能否学习执行大量指令,并零样本泛化到新任务、对象和环境中?
指令:测试了21个新的未见指令——确保每条指令中涉及的对象与技能中的一部分在训练集中存在,但排列方式不同

根据背景/物体的改变程度分成L1/L2/L3三个任务难度等级:
L1:只改变环境光照与台面布局
L2:改变环境光照与台面布局+加入放置未见物体
L3:改变环境光照与台面布局+加入放置未见物体+改变物体位置

鲁棒性:
干扰因素:对30个真实世界任务进行测试
环境背景变化:对22个真实世界任务进行测试,改变照明、视觉背景效果、台面背景(桌布等)


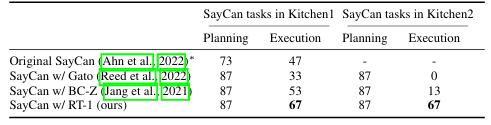
长时序跨度场景:各种方法在长时间跨度的机器人场景中泛化程度如何?
执行一系列技能,并结合多种泛化维度(技能/物体/环境)进行测试
测试了15个长时序指令,每个指令由10个左右的不同技能指令序列组成
测试结果:
其他问题:
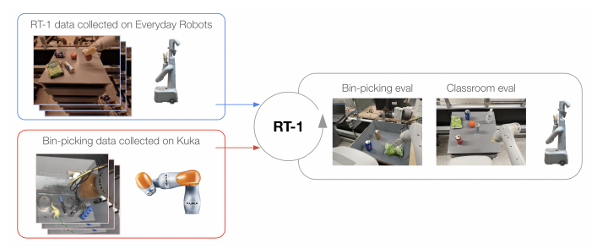
通过合并异构数据源(如模拟数据或不同机器人的数据),我们能否进一步提升所得到的模型?
合并模拟数据

合并不同机器人数据

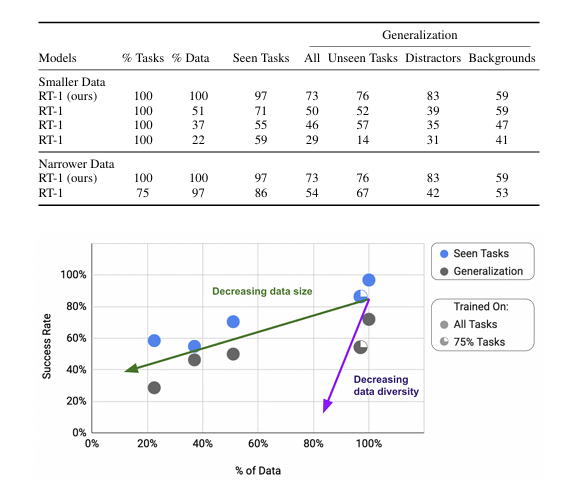
随着数据量和数据多样性的变化,泛化指标如何改变?
数据多样性比数据量更为重要
环境搭建与测试
- 代码仓库克隆
1 | git clone https://github.com/google-research/robotics_transformer.git |
- python环境配置
1 | pip install -r robotics_transformer/requirements.txt |
注意到requirements.txt中包含
1 | git+https://github.com/google-research/tensor2robot#tensor2robot |
由于该git仓库无法作为pip包直接安装,还需要克隆该仓库:
1 | git clone https://github.com/google-research/tensor2robot |
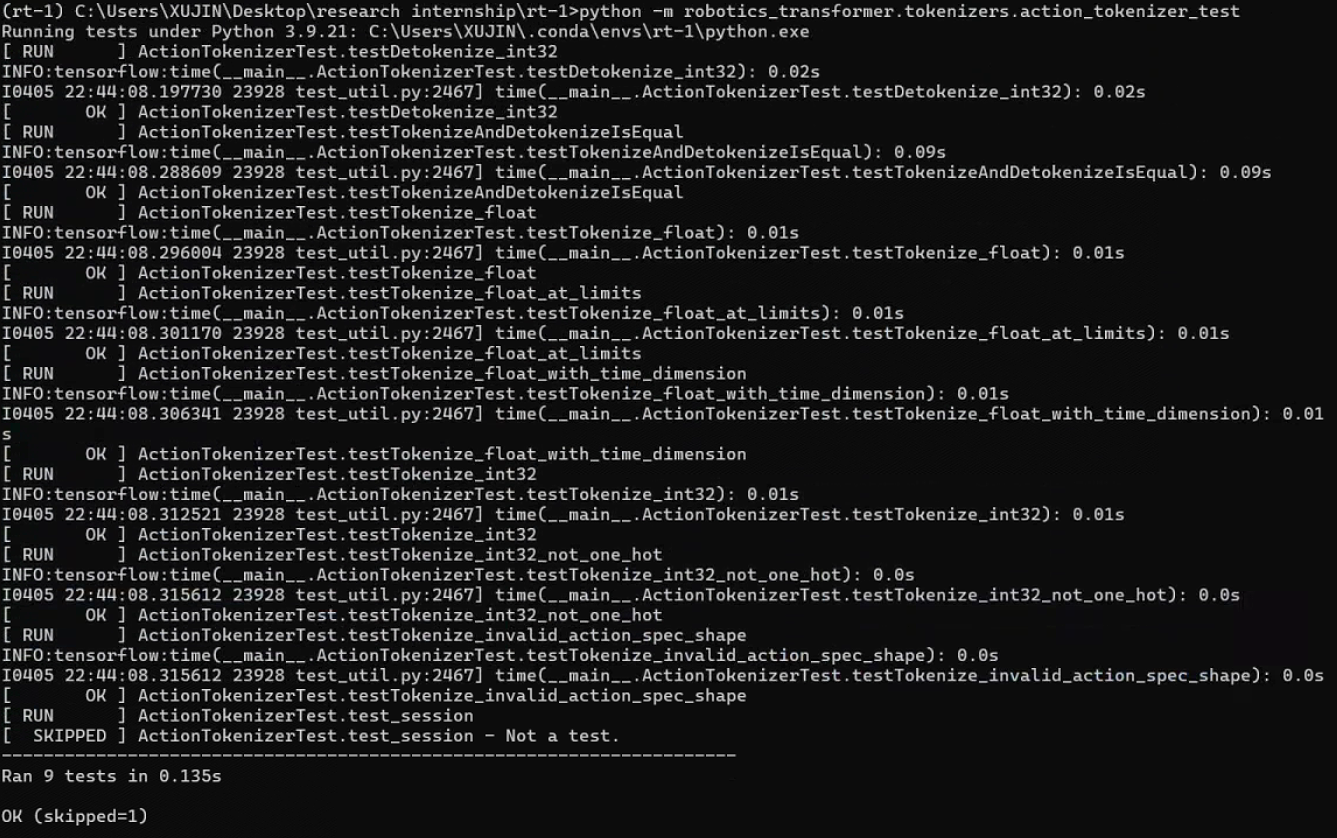
克隆完成后输入如下命令运行测试程序(这里原作github仓库中有误,将action_tokenizer.test改为action_tokenizer_test):
1 | python -m robotics_transformer.tokenizers.action_tokenizer_test |
无法正常运行,需要根据报错进行对应库版本的修正,同时根据tensor2robot仓库中的说明,使用protoc工具通过proto文件生成对应的py代码文件,具体不详细展开。
环境配置完成后,出现如下输出,说明测试程序运行成功。